Lerntheorie I: Die wissenschaftlichen Grundlagen modernen Hundetrainings – Pawlow, Skinner & Co
Vom Pawlowschen Hund, über operanten Konditionierung, Belohnung und Strafe
Von:
Ulf Weber
Zuletzt aktualisiert am: 3.3.2024

Im ersten der drei Teile über moderne Trainingsmethoden in der Hundeerziehung befassen wir uns mit der Geschichte der verhaltenswissenschaftlichen Grundlagen. Wenn Du wissen möchtest, warum wir heute Strafen vermeiden und stattdessen mit Belohnungen im Training arbeiten, im Alltag aber weder ständig belohnen müssen noch sollen, solltest Du diesen Text lesen. Er begründet, warum wir Hunden gegenüber immer konsequent sein sollten und was unter Konsequenz verstanden wird. Insgesamt gibt er Dir ein tiefes Hintergrundwissen, um selbst entscheiden zu können, nach welchen der in Teil 2 dieser Reihe dargestellten und in Beziehung zur Verhaltenswissenschaft gesetzten Erziehungsmethoden Du Deinen Hund trainieren möchtest. Wenn Du nur einen Überblick über die moderen Techniken haben möchtest, bietet sich Teil 3 an, der die Ergebnisse in aller Kürze zusammenfasst.

Pawlow & die klassische Konditionierung
Die Geschichte der Paslowschen Hunde, die im Labor des russischen Arztes Ivan Petrovic Pawlows zu sabbern begannen, wenn sie die Schritte ihres Tierpflegers hörten, ist auch der Beginn der klassischen Konditionierung und damit einer der Grundlagen moderner Hundeerziehung.
Die Geschichte der pawlowschen Hunde
Der russische Mediziner und Physiologe Ivan Petrovic Pawlow forschte ab 1890 zur nervlichen Steuerung der Verdauungsdrüsen. Für seine durch Versuche an Hunden gewonnenen Erkenntnisse zur Steuerung der Verdauung wurde er 1904 mit dem Nobelpreis geehrt.
Im Rahmen dieser Forschungsarbeit machte er die uns Hundehaltern gut bekannte Beobachtung, dass die Laborhunde zu speicheln begannen, wenn sie Futter vorgesetzt bekamen. Seine feine Beobachtungsgabe ließ ihn aber erkennen, dass die Hunde nach einiger Zeit schon zu speicheln begannen, wenn sie nur die Schritte des Tierpflegers hörten, der gewöhnlich das Futter brachte. Er schloss daraus, dass die Hunde das Geräusch der Schritte nun mit dem Futter verbunden hatten und nun die im Grunde für Hunde bedeutungslosen Schritte nun mit Futter gleichbedeutend waren und daher dieselbe Reaktion wie das Futter selbst auslösen.
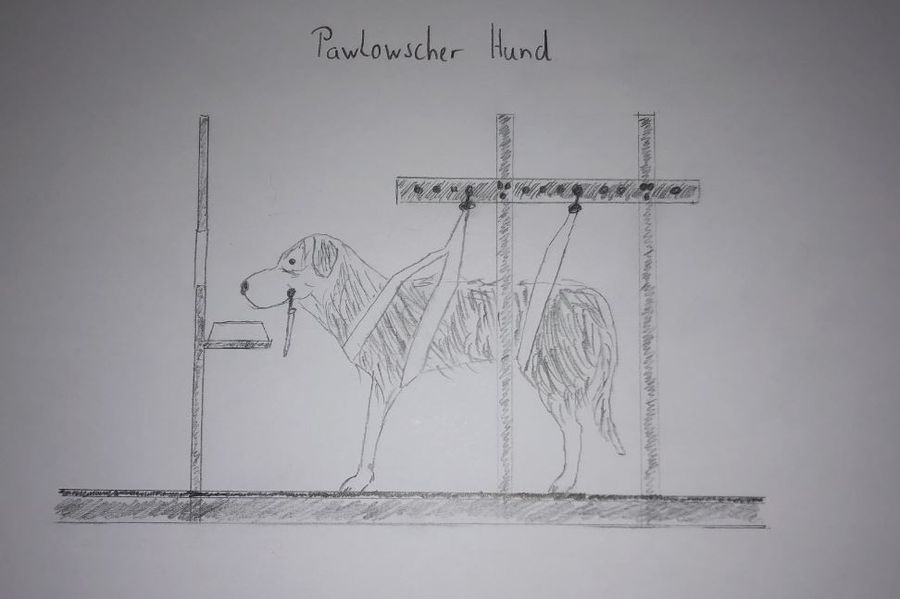
Die klassische Konditionierung oder die Reizkopplung
Im Jahr 1905 begann Pawlow, seine auf die Beobachtung seiner Laborhunde während der vergangenen 15 Jahre basierenden Vermutungen zur Reizkopplung wissenschaftlich aufzuarbeiten. Dazu stellte er seine Theorie der klassischen Konditionierung rund um das Verhältnis der folgenden unterschiedlichen Begriffe zueinander auf.
Der unbedingte Stimulus ist ein Reiz, der eine unbedingte Reaktion hervorruft. Unbedingt werden beide genannt, da die Wahrnehmung des Reizes und die Reaktionnicht gelernt werden müssen. Sie sind angeboren und die Reaktion erfolgt reflexartig, also ohne willentliche Steuerung. So ist Futter der unbedingte Reiz und der Speichelreflex die unbedingte Reaktion.
Dabei wird zwischen appetitiven oder angenehmen Reizen, wie im Falle des Futters, und aversiven oder unangenehmen Reizen unterschieden. Ein solcher aversiver Reiz wäre beispielsweise ein schmerzverursachender Stromschlag.
Ein neutraler Stimulus ist ein Reiz, den der Hund zwar wahrnimmt, der aber keine besondere Reaktion auslöst. Das trifft auf fast alles zu, was wir Menschen den Ohren und Augen unserer Hunde zukommen lassen: Worte, Gesten und Geräusche von Klickern oder Glocken. Im oben beschriebenen Fall der pawlowschen Hunde waren das zunächst die Laufgeräusche des Tierpflegers.
Aus dem neutralen Reiz wird durch die klassische Konditionierung dann ein bedingter Stimulus, der eine bedingte Reaktion auslöst, indem die beiden Reize gekoppelt werden: Die ursprünglich bedeutungslosen Geräusche wie Fußschritte, Klicker oder Worte bekommen nun für den Hund eine Bedeutung, z. B. die Erwartung, dass es gleich Futter gibt. Voraussetzung für diese Reizkopplung ist eine räumliche und zeitliche Nähe der beiden Reize. Diese Nähe wird Kontiguität genannt. Die entstandene Reizkopplung verursacht als bedingte Reaktion den Speichel-Reflex.
Die Korrektheit seiner Theorie über die Reizkopplung überprüfte er in entsprechenden Experimenten. Dabei prüfte er erst die Reaktion der Hunde auf einen neutralen Stimulus, beispielsweise das Klingeln einer Glocke oder das Ticken eines Metronoms: Nur, wenn die Hunde „unspezifisch“ reagierten, also beispielsweise nur die Ohren spitzten und sich in Richtung des Geräuschs orientierten, aber keine weiteren Reaktionen zeigten, war der Reiz tatsächlich neutral.
In der folgenden Lernphase wurden der neutrale und der appetitive Stimulus, konkret beispielsweise also das Geräusch einer Glocke und die Verabreichung von Futter, immer wieder in räumlicher und zeitlicher Nähe präsentiert, wobei diese Kontiguität auf unendlich viele Weisen hergestellt werden kann: Beispielsweise kann das Glockengeläut kurz vor der Futtergabe beginnen und dann entweder schon bei Futtergabe oder erst nach dem Fressen enden. Denkbar wäre auch, das erst geläutet wird, wenn das Futter schon gereicht ist. Pawlow teilte seine Versuchstiere nun in Gruppen ein, die dann in einer bestimmten Variante der Kontiguität konditioniert wurden.

Das Ergebnis war in vielen dieser Varianten, dass er seinen Hunden beibrachte zu speicheln, wenn sie das Geräusch einer Glocke vernahmen: Die Hunde hatten die beiden Reize gekoppelt.
Im Rahmen der Versuchsreihen wurde auch erkannt, welche Variante der Kontiguität besonders erfolgreich war und dass der neutrale Stimulus (Glockengeläut etc.) am besten und schnellsten mit dem unbedingten Reiz (Futter) verknüpft wird, um zur selben Reaktion (Speicheln) zu führen, wenn der neutrale kurz vor dem unbedingten Stimulus startet und dann gleichzeitig mit ihm weiter gegeben wird. In dem Fall spricht man von „short delayed conditioning“. Der Umstand, dass dieses „short delayed conditioning“ die effektivste und schnellste Methode ist, eine Reizassoziation aufzubauen, lässt die Wissenschaft erkennen, dass es den Lebewesen insgesamt darum geht, durch die Reizkopplung ihre Reaktionsgeschwindigkeit zu erhöhen, indem sie eben lernen, dass auf ein vorauseilendes Signal ein wichtiger Reiz erfolgt, auf den sie reagieren müssen. Somit kann schon auf das Signal hin und nicht erst auf den tatsächlichen Reiz hin reagiert werden. Der hiermit gewonnene zeitliche Vorsprung stellt einen Überlebensvorteil dar.
Pawlow stellte auch fest, dass eine hergestellte Konditionierung auch wieder abgeschwächt werden kann, nämlich dann, wenn der bedingte Reiz viele Male ohne den unbedingten Reiz gegeben wird. Auf Grund eines Übersetzungsfehlers wird hierbei von Extinktion oder Löschung gesprochen.
Die Abschwächung konnte auch nach dem zweiten Weltkrieg beobachtet werden: Menschen in häufig bombardierten Gebieten verknüpften das angsteinflößende Bombardement mit dem vorangehenden Sirenengeheul und bekamen lange Zeit nach dem Krieg schon dann Angst, wenn der Probealarm erklang. Diese Angst verlor sich aber bei vielen im Laufe der Zeit, da nach dem Alarm keine Bomben mehr fielen - die Kopplung beider Reize wurde gelöscht.
Im Grunde erkannte also Pawlow, dass ein Organismus lernen kann, einen Reiz durch einen anderen zu ersetzen und dann dieselbe Reaktion zu zeigen. Diese war zunächst eine Reflexreaktion, über die das Lebewesen keine „willentliche“ Entscheidung treffen konnte und diese angeboren und nicht zu erlernen war.
Die Klassische Konditionierung in der Hundeerziehung
Eine praktische Anwendung dieser Technik in Reinform stellt die Gewöhnung an den Klicker dar, durch die der Hund lernt, dass das Geräusch des Klickers für ihn Futter und damit etwas positives bedeutet.
In leicht abgewandelter Art aber auch bei der frühen Konditionierung auf ein Rückrufsignal, wie in "Führung - Freifolge - Hund-Mensch-Bindung, der sichere Rückruf und die Konditionierung – wie hängt das alles zusammen?" zu lesen ist. Hier ist zu bedenken, dass entsprechend der Erkenntnis der Abschwächung dem bedingten Reiz des Clickers immer eine Futtergabe erfolgen soll, damit der bedingte Reiz nicht an Stärke und Bedeutung für den Hund verliert.
Edward Lee Thorndikes Puzzle-Boxen & die Instrumentelle Konditionierung
Zur selben Zeit interessierte sich der amerikanische Psychologe Edward Lee Thorndike für Lernverhalten und entwickelte für die experimentelle Forschung seine Puzzle-Boxes. Aus den in seinen Versuchen gewonnen Erkenntnissen formulierte er die Grundlagen der Instrumentellen Konditionierung, die ebenfalls großen Einfluss auf die moderne Hundeerziehung hat.
Die Forschung Thorndikes
Der 1874 in den USA geborene Edward Lee Thorndike konzentrierte sich als Psychologe auf Verhaltensforschung, kam also im Gegensatz zum Physiologen Pawlow vom Fach und forschte seit 1898 zum Lernverhalten von Tieren. Er definierte im Rahmen seiner Forschungsarbeit drei Gesetze, die zur Grundlage der Theorie der instrumentellen Konditionierung führte. Damit beschäftigte er sich „offiziell“ zwar sieben Jahre vor Pawlow mit Verhaltensforschung, andererseits forschte Pawlow seit 1890 bereits an Hunden zu deren Verdauungsdrüsen, was bei ihm zu ersten Erkenntnissen zur Reizkopplung führte.
Es ist also nicht ganz klar, wer von beiden zeitlich der erste war. Da aber die komplexere Instrumentelle Konditionierung bereits aus der Klassischen Konditionierung bekannte Begriffe verwendet, haben wir diese als erste erklärt.
Thorndikes Forschungsziel – Wie lernt ein Lebewesen?
Thorndike wollte unter anderem herausfinden, auf welche Weise ein Organismus, also ein Tier oder Mensch, lernt.
Bei dieser Fragestellung war er sehr von Darwins Evolutionstheorie inspiriert. Diese besagt, dass die Natur zufällige Varianten einer Art entwickelt. Die Varianten, die einen lebenswichtigen Vorteil besitzen und somit besser an die durch die Umwelt gegebenen Aufgaben angepasst sind, überleben und vermehren sich. Die weniger gut angepassten, überleben seltener und vermehren sich weniger und sind vom Aussterben bedroht. Diesem „Survival oft he fittest“ liegt also das Prinzip des Versuchs und Irrtums zu Grunde: Es werden Varianten einer Art ausprobiert und die Irrtümer dabei sterben aus.
Denkbar war nun, dass sich das Prinzip des Trial and Error auch auf das Erlernen einer Reaktion durch ein Individuum anwenden ließe. Die Alternative dazu wäre ein Lernen durch plötzliche Einsicht.
Um dies erforschen zu können, musste er sich eine Versuchsanordnung überlegen, die es ihm erlaubt, ein Versuchstier vor ein zu lösendes Problem zu stellen, das als Stimulus für eine Reaktion dient. Die Lösung des Problems darf dem Tier vor Beginn der Versuchsreihe nicht bekannt sein, damit die Reaktion des Tieres darin besteht, herauszufinden und zu lernen, wie der Stimulus beseitigt werden kann.
Im Gegensatz zu Pawlows klassischer Konditionierung ging es ihm also nicht darum, wie ein Lebewesen lernt, einen Reiz durch einen anderen zu ersetzen und dann auf beide Reize gleich zu reagieren. Vielmehr ging es Thorndike darum, dass das Lebewesen lernt, auf einen Reiz hin eine bestimmte Reaktion zu zeigen.
Thorndikes Versuchsaufbau: Die auf Deutsch Problemkäfig genannte Puzzle Box
Die von Thorndike 1898 entwickelte Puzzle Box, Rätselkäfig oder Problemkäfig zu Deutsch, erfüllt die oben genannten Kriterien. Sie ist im Grunde genommen ein Käfig mit einer einfachen Vorrichtung zur Selbstbefreiung. Vor die Box wurde Futter als zusätzlicher Stimulus für das Versuchstier platziert. Die Vorrichtung zur Selbstbefreiung des Versuchstiers kann ein zu drückender Knopf, eine zu betretende Platte oder Wippe oder ein zu ziehendes Seil sein.
Als Labortiere verwendete er vorwiegend Hühner, Hunde und Katzen. Zum Zeitpunkt des Versuchs musste das jeweilige Tier hungrig sein, damit es das Ziel verfolgt, aus dem Käfig zu entkommen und zum Futter zu gelangen.
So waren die Tiere mit drei Stimuli oder Problemen konfrontiert:
a. Entzug der Freiheit als äußerer Reiz
b. leerer Magen als innerer Reiz
c. Futter, das sie wahrnahmen, das aber wegen des Freiheitsentzugs nicht leicht zu erreichen war, als äußerer Reiz.
Diese Probleme oder Stimuli verursachen bei den Tieren eine Vielzahl verschiedener Reaktionen oder Verhaltensweisen. Nun geht es für die Tiere darum, die erfolgreiche Verhaltensweise oder Reaktion zu finden, die das Problem löst und den Käfig öffnet und außerdem zu lernen, welche der Verhaltensweisen zuverlässig und damit immer das Problem löst.
Wie liefen die Versuche Thorndikes ab?
Thorndike sperrte nun ein hungriges Tier in die Puzzle Box, um das Verhalten des jeweiligen Tiers zu beobachten und zu dokumentieren. Wurde ein Tier erstmalig in den Käfig gesetzt, bewegte es sich erwartungsgemäß auf zufällige Art und Weise, um dem Käfig zu entkommen. Ebenso zufällig kann hierbei auch der Mechanismus zur Selbstbefreiung betätigt werden, was je nach Anordnung und daraus folgendem Schwierigkeitsgrad nicht jedem Tier gelungen ist.
Thorndike maß nun die in vielen Fällen recht lange Zeit, die das Tier benötigte, um sich zu befreien und wiederholte das Ganze mehrfach. So konnte er die Zeiten, die bei den jeweiligen Durchläufen des Versuchs erzielt wurden, miteinander vergleichen und eine sogenannten Lernkurve erstellen. Anhand dieser Lernkurve wiederum konnte abgelesen werden, ob die Tiere überhaupt lernen und wenn ja, ob das Lernen mit einem Aha-Moment der Einsicht verbunden ist oder über Versuch und Irrtum und damit graduell in einer sanften Kurve erfolgt.
Würde gar nicht gelernt, dürfte die benötigte Zeit im Laufe der Versuchsdurchgänge nicht kürzer werden: In statistisch immer gleichen Zeitintervallen würde aus Zufall der Mechanismus ausgelöst werden.
Bei einem Aha-Moment hätte die für die Selbstbefreiung benötigte Zeit vom ersten Durchlauf bis zu dem Durchlauf mit dem Aha-Moment gleich lang bleiben müssen, um dann sprunghaft auf eine viel kürzere Spanne zu sinken, die dann immer gleichbliebe.
Tatsächlich stellte Thorndike aber fest, dass im Durchschnitt aller Versuchstiere die Zeiten, die für die Selbstbefreiung benötigt wurden, von Durchgang zu Durchgang kürzer wurden. Dies erfreute Thorndike sicher sehr, scheint diese Art zu lernen doch demselben Prinzip zu folgen, wie die ihn zu seiner Forschung inspirierende Evolutionslehre seines Vorbilds Charles Darwin.
Im Falle der Katzen stellte er darüber hinaus fest, dass sie das Futter gar nicht wahrnahmen, wenn sie in den Käfig gesperrt waren. Diese Tiere sind so freiheitsliebend, dass der Freiheitsentzug als unangenehmer Reiz völlig ausreicht und sie dem Käfig entkommen möchten, weil es ihnen Unbehagen bereitete, auf solch engem Raum eingesperrt zu sein. Sie bissen und krallten alles im Käfig an, wohl in der Hoffnung, den Käfig so kaputt machen, entkommen zu können und letztlich den aversiven Reiz beenden zu können. Wie wir im im folgenden Block über die Entstehung der operanten Konditionierung sehen werden, entspricht das einer negativen Verstärkung.
Was schloss Thorndike aus seinen Versuchen?
Die drei wesentlichen theoretischen Erkenntnisse, die er aus seinen Beobachtungen und Messungen gewann, bilden die Grundlage für die Instrumentelle Konditionierung.
Das Gesetz der Übung:
Aus der Tatsache, dass die Versuchstiere mit jeder Wiederholung der Selbstbefreiung schneller wurden, schloss er, dass ein zu erlernendes Verhalten vielfach wiederholt werden muss, also geübt werden muss, um es sicher zu lernen.
Dass es sich tatsächlich so verhält, wissen wir nicht nur aus unserer Schulzeit, in der wir an uns selber beobachten konnten, dass wir beispielsweise erst durch wiederholtes Aufsagen des kleinen Einmaleins aus dem Stegreif wussten, was 3 x 6 oder 6 x 7 ergibt. Auch bezogen auf sportliche Bewegungsabläufe wissen wir, dass Übung den Meister macht.
Klar, dass das auch so für unsere Hunde gilt: Eine hohe Anzahl von Wiederholungen sichert, dass Dein Hund versteht, was Du wann von ihm willst.
Gesetz der Bereitschaft:
Thorndike experimentierte vorwiegend mit Hühnern, Hunden und Katzen.
Er konnte beobachten, dass Katzen auch ohne vor dem Käfig platziertem Futter nach Freiheit strebten, während die hungrig gehaltenen Hühner und Hunde vor allem nach dem vor dem Käfig platzierten Futter strebten und ohne das vor dem Käfig platzierte Futter nicht im selben Maß versucht hatten, sich zu befreien.
Er schloss daraus, dass für das Erlernen neuen Verhaltens, in dem Fall das der Selbstbefreiung aus dem Käfig, eine Bereitschaft vorliegen muss. Diese Bereitschaft zu lernen ergibt sich aus einem Bedürfnis, das der lernende Organismus nur befriedigen kann, wenn er lernt und das sich seinerseits aus einem Reiz oder Stimulus ergibt: Die Katze hat das Bedürfnis nach Freiheit, die anderen Tiere hatten das Bedürfnis zu fressen. Beide Bedürfnisse konnten nur befriedigt werden, wenn die Tiere lernten, sich zu befreien.
Ein Organismus wird also nach Thorndikes Meinung nur dann bereit oder motiviert sein, neues Verhalten zu lernen, wenn er ein erfolgreiches Instrument zur Verbesserung seiner Situation oder zur Lösung eines Problems sucht.
Thorndike betrachtet also das Verhalten eines Lebewesens als Instrument zur Herstellung eines für das Lebewesen möglichst angenehmen Zustands. Dieser Denkansatz war wohl für Prof. Dr. Gerd Mietzel ausschlaggebend, diesen Ansatz als Instrumentelle Konditionierung zu definieren.
Gesetz der Auswirkung:
Wenn Thorndike also sagt, dass alles Verhalten eines Lebewesens ein Instrument zur Befriedigung von Bedürfnissen und damit zur Lebensverbesserung ist, liegt es nahe, dass Auswirkung des Verhaltens eine wesentliche Rolle spielt.
In seinen Experimenten konnte er beobachten, dass die Verhaltensweisen, die den Käfig nicht öffneten und daher kein positives Ergebnis brachten, seltener von den Tieren ausprobiert wurden. Auf diese Weise schafften es die Tiere im Laufe der Zeit, viele nicht erfolgreiche Verhaltensweisen gar nicht mehr zu versuchen und dadurch die Zeit, die sie brauchten, sich zu befreien, zu senken. Übrig blieb dann nur die erfolgreiche Verhaltensweise, die dann früher und vor allem öfter verwendet wurde.
Thorndikes Gesetz der Auswirkung besagt also, dass jedes Lebewesen bestrebt ist, Verhaltensweisen zu lernen, die ein Problem lösen und denen somit angenehme und belohnende Konsequenzen folgen. Umgekehrt geht Thorndike davon aus, dass es lernen will, Verhaltensweisen zu vermeiden, die die Situation nicht verbessern oder gar verschlimmern, denen also negative und somit bestrafende Konsequenzen folgen.
Die Instrumentelle Konditionierung zusammengefasst
Thorndike sagt also zusammengefasst, dass ein Lebewesen dann bereit zu lernen ist, wenn es einem Stimulus ausgesetzt ist, den es als unangenehm und daher als zu lösendes Problem ansieht.
In dem Fall wird es eine Reaktion in Form verschiedener Verhaltensweisen ausprobieren. Viele dieser Verhaltensweisen führen zu keinem angenehmeren Zustand, sind also Fehler, und werden daher weniger stark mit der Situation in Verbindung gebracht. Dieses Prinzip wird Trial and Error, also Versuch und Fehler, genannt.
Zufällig wird aber eine dieser Verhaltensweisen die Lösung und somit einen angenehmeren Zustand bringen. Der angenehme Reiz, der von dieser Verbesserung ausgeht, wirkt als die Belohnung und damit als Verstärker der entsprechenden Verhaltensweise, die daher stärker mit der Situation verbunden wird. Daher steigt die Wahrscheinlichkeit, dass sie in ähnlicher Situation erneut versucht wird.
Noch hat das Lebewesen aber nicht eindeutig gelernt, welche Verhaltensweise erfolgreich war, obwohl eine leichte Verbindung zwischen dem Problem und der lohnenden Verhaltensweise entstanden ist. Tritt das Problem aber häufig genug auf, wird es also häufig genug geübt, wird die Verbindung zwischen Problem und der Befriedigung bringenden Lösung immer enger und dem Lebewesen immer klarer, welches Verhalten die Lösung brachte. Das bedeutet, dass häufiges Üben einer Situation das Lernen befördert.
Was bedeutet das für die Hundeerziehung?

Einleuchtend ist, dass häufige Wiederholungen von Übungen auch im Hundetraining sinnvoll sind.
Zu überdenken ist allerdings, dass die Instrumentelle Konditionierung voraussetzt, dass der Hund als Stimulus ein Problem benötigt und dann mit seinem Verhalten versucht, dieses Problem zu lösen. Das führt dazu, dass die Lösung des Problems auch gleichzeitig die das Verhalten verstärkende Belohnung darstellt. Damit kann also erklärt werden, wie ein Hund lernt, sich zu kratzen: Es juckt ihn und wenn er sich an der entsprechenden Stelle kratzt, bringt das Kratzen Erleichterung. Sicherlich kann Dein Hund so auch lernen, welche Verhaltensweisen seinen Hunger stillen:
Dich bettelnd anschauen, wenn Du am Tisch sitzt:
Bekommt er was, wird er häufiger betteln
Bekommt er nichts, wird er seltener betteln
Es wird aber nicht klar, wie Du Deinem Hund den Grundgehorsam über diese Methode beibringen kannst: Es fällt mir kein Weg ein, wie Du Dein Problem, beispielsweise Deinen Wunsch, dass Dein Hund zu Dir kommt, zu seinem Problem machen kannst. Sein Problem im Sinne Thorndikes würde schließlich bedeuten, dass das Herankommen Lösung wäre, die die Situation Deines Hundes so verbessert, sodass beide Verhaltensweisen jeweils „selbstbelohnend“ werden. Solche Situationen werden zwar vorkommen, vielleicht kommt Dein Hund immer zu Dir gelaufen, wenn er Angst hat und daher Schutz bei Dir sucht. Aber einen sicheren Rückruf hast Du dann immer noch nicht: Dein Hund kommt zu Dir, wenn er darin eine Lösung sieht, nicht, wenn Du das möchtest.
Vielleicht hatte der US-amerikanische Psychologe B. F. Skinner ähnliche Gedanken, als er an Thorndikes Arbeit anschloss und sich dabei zunächst auf das Gesetz der Auswirkung konzentrierte und in seinen Versuchen auf ein zu lösendes Problem verzichtete.
B. F. Skinner & die Anfänge der operanten Konditionierung
Die operante Konditionierung B. F. Skinners legte das Fundament nicht nur der modernen Hunderziehung. Wie er die positive Verstärkung erforschte und was seine Bedeutung für die Pädagogik des letzten Jahrhunderts mit der TV-Serie "Die Simpsons" zu tun hat, zeigen die folgenden Passagen.
Wer war B. F. Skinner?
Als Pawlow und Thorndike mit ihren Forschungen zur Konditionierung begannen, war noch nicht abzusehen, wie groß der Einfluss des 1904 in den USA geborenen Burrhus Frederic Skinners durch die von ihm entwickelte operante Konditionierung auf die Lerntheorie und die angewandte Pädagogik in der Mitte des letzten Jahrhunderts werden würde.
B. F. Skinner wurde im Rahmen seiner Arbeit in einer Buchhandlung auf die in der Zeit seiner Geburt entwickelte Klassische Konditionierung aufmerksam. Das Thema erschien ihm so spannend, dass es ihn zu einem Studium der Psychologie inspirierte und er sich 1928 zu diesem Zweck an der Harvard University einschrieb. Dort wird er auch mit der Forschungsarbeit Thorndikes in Berührung gekommen sein, die er dann vorantrieb und modifizierte, unter anderem mit der Weiterentwicklung der Puzzle Box Thorndikes zur Skinner Box.
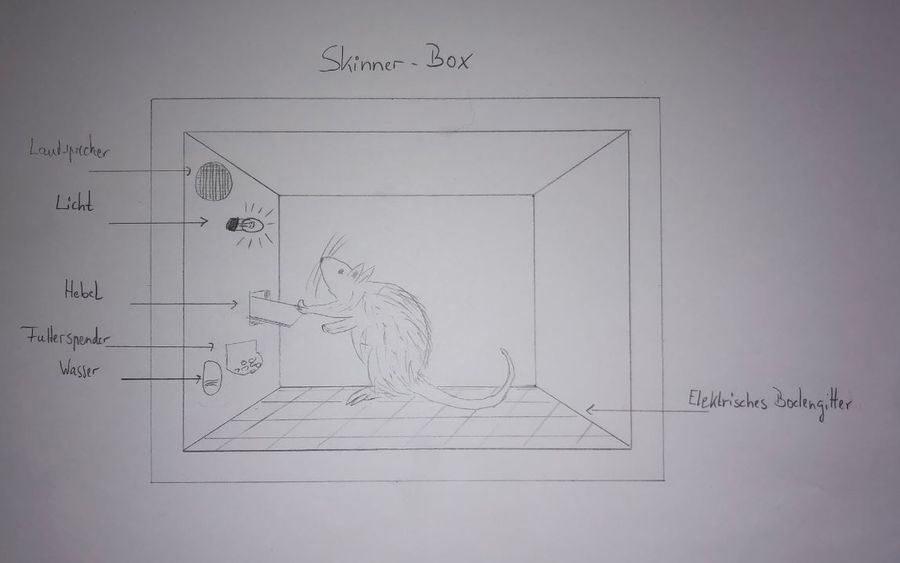
Die im Folgenden beschriebene operante Konditionierung ist ein breites und thematisch tiefes Feld: Skinner beschäftigte sich zunächst mit dem, was er positive Verstärkung nannte. Das führte ihn zu Experimenten zur negativen Verstärkung sowie der positiven und negativen Bestrafung, die er im Kontingenzschema zusammenfasste. Weiterhin erforschte er, ob es Hinweisreize gibt, die ein Verhalten auslösen können ebenso, wie die Frage, welche Auswirkung es hat, wenn eine Verstärkung nicht auf jedes gewünschte Verhalten erfolgt und entwarf dazu Versuche zu Verstärkungsplänen. Zur schnelleren Konditionierung entwickelte er das Shaping und für komplexere Verhaltensweisen das Chaining, beides Trainingsmethoden, die heute noch im Tier- und Hundetraining angewendet werden.
Skinner krönte seine Forschung mit der Entwicklung des programmierten Unterrichts, der in der Mitte des letzten Jahrhunderts immensen Einfluss auf die Pädagogik hatte. Die dadurch erreichte Bekanntheit Skinners, zeigt sich in der Tatsache, dass Matt Groening in der Comic Serie „Die Simpsons“ den Rektor von Springfields Grundschule, Seymour Skinner, nach ihm benannte und Skinner daher auch heute noch vielen Simpsons-Fans ein bekannter und mit dem Schulwesen verbundener Name ist.
In seinem 1948 veröffentlichten Roman „Walden Two“ entwarf er die Vision einer, durch positive Verstärkung, auf moralisch einwandfreies Zusammenleben konditionierten aber damit auch gesteuerten Gesellschaft. Dieser Ansatz rief viele Kritiker auf den Plan, die den mit der Menschenwürde verbundenen freien Willen in Gefahr sahen. Dieser philosophische Aspekt der Konditionierung fand durch Stanley Kubriks Film „The Clockwork Orange“ Einzug in die Populärkultur. Dort wird der extrem gewalttätige Protagonist Alex durch klassische Konditionierung an weiteren Gewalttaten gehindert. Wird hier noch ein durchaus sinnvoller Zweck vorausgesetzt, stellt sich aber auch die Frage, wer denn in einer solchen Gesellschaft die zu verstärkenden Verhaltensweisen und Werte festlegen würde: Diktatoren wie Hitler, Stalin oder Mao hätten sicherlich an diesen Techniken ihren Spaß gehabt.
Skinner war dabei immer wichtig, dass Verhaltenspsychologie streng wissenschaftlich betrieben wird. Für ihn bedeutete das, dass nur Aussagen über messbare Größen getroffen werden können. Entsprechend werden innere Vorgänge wie Gedanken oder Gefühle von ihm nicht beachtet, sondern in eine unergründliche Black-Box verbannt. So konnte er auch in Interviews auf kritische Nachfragen zu den oben genannten moralischen Fragen gelassen antworten, dass die Wirkung der operanten Konditionierung nun einmal wissenschaftlich bewiesen wäre und die Konditionierung jedes Verhalten formen würde, dabei aber nichts dafür könne, wer sie mit welchem moralischen Grundgerüst anwende.
Teilweise wurden die Frage experimentell von Skinner selbst, teilweise aber auch von seinen Kollegen oder auch von späteren Forschergenerationen beantwortet. Da die Fragen und damit die folgenden Experimente teilweise parallel stattfanden, aber teilweise eben nicht mehr von Skinner, sondern seinen Nachfolgern durchgeführt wurden, berufe ich mich im Folgenden häufig auf Skinner, wenn es um die Anfänge geht. Zum leichteren Verständnis des komplexen Themas fasse ich aber den aktuellen Stand der Forschung zusammen, auch wenn hier nicht nur Skinners Erkenntnisse einfließen.
Die Forschung Skinners und die positive Verstärkung
Zunächst befasste sich Skinner mit dem, was er später positive Verstärkung nennen würde und was heute die weitverbreitetste Grundlage für Tiertrainingsmethoden ist.
Skinners Forschungsziel – Wie lehrt man ein Lebewesen?
Skinner befasste sich sowohl mit der klassischen Konditionierung Pawlows als auch mit Thorndikes (instrumentellen) Konditionierung. Beide befassen sich mit dem lernenden Organismus.
Im Falle der klassischen Konditionierung wird gelernt, einen eigentlich bedeutungslosen Reiz einem wichtigen Reiz gleichzusetzen und auf beide mit demselben Reflex zu reagieren.
Die instrumentelle Konditionierung beschreibt, wie ein Organismus lernt, seine Reaktion auf einen äußeren Reiz anzupassen. Um überhaupt lernwillig zu sein, muss eine Lernbereitschaft hergestellt werden. Daher darf der äußere Reiz für den lernenden Organismus nicht angenehm sein, sondern muss ein Problem darstellen. Der Organismus wird durch dieses Problem, das er lösen möchte, motiviert zu lernen. Das richtige Verhalten wird belohnt, oder, wie die Forscher sagen, verstärkt, durch die Verbesserung der Lebenssituation des Lernenden: Die problemlösende Reaktion oder Verhaltensweise wird verstärkt, indem das Problem wegfällt und ist damit selbstbelohnend. Damit kann also gut beschrieben werden, wie ein Organismus in einer mit problematischen Reizen angefüllten Umwelt zu überleben lernt. Beispielweise, wie er erfolgreich auf einen Rivalen reagieren kann oder wie eine Jagd erfolgreich aufzubauen ist, wenn er hungrig ist.
Wie wir festgestellt haben, fällt es uns und wohl jedem Lehrer aber schwer, zu jedem Lerninhalt (Hier, Sitz, Platz, Fuß etc. im Falle unserer Hunde) ein Problem für den lernenden Organismus zu konstruieren. Thorndikes Theorie lässt also die Frage offen, wie denn ein Lehrer oder Trainer in das Modell passt, vor allem, wenn dieser Verhaltensweisen vermitteln möchte, die kein nahe liegendes Problem für den lernenden Organismus lösen.
Skinner wollte nun herausfinden, ob die „Effektivität der Außenkontrolle“ gesteigert werden kann. Da nach seiner Meinung zu den inneren Vorgängen oder Zuständen wie Hunger, Leid, Langeweile oder Motivation nur Spekulationen angestellt werden können, lässt er diese Aspekte in seinen Überlegungen und Ansätzen außen vor. Stattdessen werden nur Reaktionen und Reize, die im Fall der positiven Verstärkung die appetitiv/angenehm wirkenden Auswirkungen der Reaktionen darstellen, einzeln betrachtet und messbar gemacht.
In der Praxis geht es hierbei also um Kontrolle oder den Einfluss eines Lehrers oder Trainers auf den Lernenden, also die Funktionsweise des Lehrens. Ansetzen wollte er hier vor allem bei Thorndikes Gesetz der Auswirkung. Hierbei ging es vor allem um den Effekt eines dem immer noch als „Reaktion“ bezeichneten Verhalten nachgelagerten Reizes, der angenehm/appetitiv oder unangenehm/aversiv auf den lernenden Organismus wirken kann. Insofern kann auch gesagt werden, dass der Lehrer die Umwelteinflüsse des Lernenden weitgehend kontrollieren und steuern muss, wenn er Lehren möchte. Am Ende dieses Prozesses steht Skinners Theorie vom programmierten Unterricht für Kinder, bei dem die positive Verstärkung automatisiert erfolgt.
In unzähligen unterschiedlichen Versuchen mit Tieren gemessene Zusammenhänge zwischen der Auftretenswahrscheinlichkeit eines bestimmten Verhaltens und der ebenso bestimmten Konsequenzen daraus übertrug er in Fachsprache, um damit das Verhalten von Tieren und auch Menschen zu beschreiben.
Skinners Versuchsaufbau für die positive Verstärkung: Die Skinner Box

Um Versuche zur positiven Verstärkung machen zu können, bei denen Reize kontrolliert verabreicht und die entsprechenden Reaktionen einzelner Organismen ohne weitere Einflussgrößen beobachtet und gemessen werden können, entwickelte Skinner die Problem Box Thorndikes weiter. Wichtig war dabei, dass das „Problem“ aus Thorndikes Versuchen entfiel: Skinner baute deshalb einen „reizarmen“ Käfig. Reizarm bedeutet, dass eben keine vor dem Käfig aufgestellte Futterration als auslösender Reiz für eine Reaktion verwendet wurde, wie dies noch Thorndike machte. Aber, genau wie Thorndike, platzierte auch Skinner immer nur ein Versuchstier in der Box, damit nicht die Probanden sich gegenseitig beeinflussen. Dieser Käfig bestand auch nicht aus Draht, sondern war weitgehend geschlossen und wurde später als Skinner Box bekannt.
Das war allerdings nicht das einzige wegweisende Merkmal der Skinner Boxen, die mit allerlei automatischer Technik ausgerüstet wurden. Zum einen versah er sie mit einer Futterschale, in die von außen über eine automatische Vorrichtung in Reichweite des Versuchstiers gebracht und wieder entfernt werden konnte. Diese automatische Vorrichtung wiederrum konnte das Versuchstier von innen durch das zu lernende Verhalten auslösen.
Außerdem war die ganze Apparatur mit einer Messeinheit verbunden, die sowohl die verstrichene Zeit als auch die Anzahl der „richtigen“ Reaktionen dokumentierte, um die Lernkurve messen und darstellen zu können.
Skinner verwendete als Versuchstiere vor allen Dingen Tauben, aber auch Ratten und andere an Käfighaltung gewöhnte Tiere. Der Vorteil dieser Tiere lag darin, dass der Aufenthalt in diesen Käfigen und der damit verbundene Freiheitsentzug nicht als solches schon einen problembehafteten Reiz lieferte. Vor den eigentlichen Versuchen maß er bei normaler Ernährung deren Gewicht, um nach einiger Zeit die Futterrationen so zu kürzen, dass die Tiere zum Zeitpunkt der Versuchsreihe nur noch 80 % ihres eigentlichen Gewichts wogen. Dies sollte sicherstellen, dass sie die Gabe von Futter als einen angenehmen Reiz empfanden.
Nun kann man sagen, dass der daraus resultierende Hunger ja doch wieder ein Problemreiz ist. Bei beiden, Thorndike und Skinner, dient der Hungerreiz dazu, dass das gereichte Futter auch tatsächlich als angenehmer Reiz empfunden wird.
Der Unterschied zwischen Thorndikes Puzzle-Box und der Skinner-Box liegt allerdings darin, dass der Freiheitsentzug der eigentliche Problemreiz bei Thorndike ist und davon ausgegangen werden kann, dass jedem Versuchstier schnell klar wird, dass es aus dem Käfig raus muss, um an das Futter zu kommen. Die Versuche Skinners vermeiden aber durch die Auswahl der Tiere und die Tatsache, dass das Futter innerhalb des Käfigs verfügbar gemacht wird, dass der Freiheitsentzug zu einem Problemreiz aufgebaut wird.
Im weiteren Verlauf seiner Forschung wurden die Skinner-Boxen komplexer, wie wir noch sehen werden.
Wie liefen die ersten Versuche Skinners zur positiven Verhaltensverstärkung ab?
Nun nahm er seine Versuchstiere und setzte sie wiederholt einzeln in eine der Boxen und ließ sie sich frei bewegen und dokumentierte ihr verhalten. In einem ersten Schritt wurde gemessen wie oft die Tiere das gewünschte Verhalten in einem gewissen Zeitraum zeigen, wenn diesem Verhalten keine Futtergabe folgt. Ohne irgendeinen besonderen Reiz zeigten die Tauben diverses Verhalten. Unter anderem begannen sie, mit ihren Schnäbeln den Boden und die Wand zu bepicken. Dabei pickten sie irgendwann auch auf den Auslöser für den Mechanismus, der diese Tatsache vermerkte. So konnte Skinner die Auftretenswahrscheinlichkeit des gewünschten Verhaltens ohne Verstärkung bestimmen. Diese Auftretenswahrscheinlichkeit wird Basisrate oder Baseline genannt.
Im nächsten Schritt werden die Tiere nun wieder in die Box gesperrt und verhalten sich, wie schon zuvor. Allerdings wird durch das Picken auf den Schalter nun nicht mehr nur der Mechanismus zur Dokumentation ausgelöst, sondern es wurde auch die als positive Verstärkung dienende Futterschale in Reichweite des Tieres gebracht.
In der Folge aus wiederholten Versuchen wurde beobachtet, dass im Laufe der Zeit die Tiere den Auslöser häufiger betätigten und somit auch häufiger Futter bekamen, als im ersten Durchlauf, als es noch kein Futter als Verstärker gab.
Da es in der Skinner Box keine anderen Reize oder Einflüsse gab, war offensichtlich, dass die Tiere lernten, positiv verstärktes und somit lohnendes Verhalten häufiger zu zeigen, auch wenn sie kein offensichtliches Problem zu lösen haben.
In einem letzten Schritt prüfte Skinner, ob die schon aus der klassischen Konditionierung bekannte Löschung auch hier eine Rolle spielt. Zu diesem Zweck wurde die Skinner Box so modifiziert, dass sie zwar weiterhin die Zeit und das Picken gemessen und aufgezeichnet wurde, aber kein Futter mehr für das richtige Verhalten verabreicht wurde. Damit war sie wieder in dem Zustand, den sie auch im ersten Schritt hatte. So konnte gezeigt werden, dass nun zunächst die Verhaltensweise deutlich häufiger gezeigt wird, als vor der Konditionierung. Da aber keine Verstärkung mehr erfolgt, nimmt nach kurzer Zeit die Auftrittswahrscheinlichkeit des konditionierten Verhaltens in einem gewissen Muster stark ab: Das Verhalten wird nicht für eine gewisse Zeit nicht mehr gezeigt, wenn keine Verstärkung erfolgt. Nach einiger Zeit kommt es zu der sogenannten Spontanerholung, bei der das Verhalten erneut einige Male gezeigt wird, um zu prüfen, ob es doch noch eine Verstärkung gibt, um dann wieder in eine Phase ohne das Verhalten überzugehen. Im Laufe der Zeit werden die Phasen ohne das Verhalten größer und entsprechend sinkt die Auftrittswahrscheinlichkeit des entsprechenden Verhaltens.
Welche Schlüsse ergaben sich aus Skinners Versuchen zur positiven Verstärkung?
Der appetitive (angenehme) Reiz, der von dem Futter ausgeht, wurde von Skinner „positiver Verstärker“ genannt. Hierbei ist ihm wichtig, dass ein Reiz immer nur dann ein Verstärker ist, wenn das ihm vorangegangene Verhalten so beeinflusst wird, dass es künftig häufiger gezeigt wird, also die Auftrittswahrscheinlichkeit des Verhaltens steigt. Positiv wird der Reiz dadurch, dass er nach dem Verhalten beginnt oder erscheint.
Skinner wusste nun also, dass die positive Verstärkung funktioniert, auch wenn kein „Problemreiz“ den Organismus motiviert, überhaupt aktiv zu werden. Allerdings erkannte er auch, dass das konditionierte Verhalten schnell wieder gelöscht wird, wenn die Verstärkung wegfällt.
Diese Erkenntnisse warfen neue Fragen auf, die Skinner zu weiterer Forschung inspirierten, wie wir im Folgenden sehen werden. Daneben gibt es aber auch Anlass zur Kritik an Skinner, stellt doch seine Definition eines positiven Verstärkers einen Zirkelbezug her. Diesen Punkt werden wir in Block 6 dieses Artikels und in diesem Block des zweiten Teils dieser Serie über die praktische Hundeerziehung wieder aufgreifen.
Die Forschung Skinners zu negativer Verstärkung und Bestrafungen sowie dem Kontingenzschema
Skinner war klar, dass es nicht nur appetitive Reize gibt, sondern auch aversive, also unangenehm empfundene. Außerdem konnten beide Arten von Reizen als Konsequenz eines Verhaltens beginnen oder enden. Der Begriff der Kontingenz entstammt dem Lateinischen und wird mit „Möglichkeit“ übersetzt. Skinner ging es bei diesem Begriff also darum, dass eine Reaktion oder klarer: ein zu konditionierendes Verhalten mit 100%iger Sicherheit, also der sichersten Möglichkeit, die Gabe oder den Wegfall eines bestimmten Reizes vorhersagt, da diese Konsequenz der Reaktion immer folgt.
Skinners Forschungsziel – Wie wirken aversive und appetitive Reize, wenn sie nach einem Verhalten entweder enden oder beginnen?
Skinner fragte sich nun, welche Beobachtungen gemacht werden können, wenn als Konsequenz eines Verhaltens statt des bei der positiven Verstärkung üblichen appetitiven Reizes ein aversiver Reiz gegeben wird. Zu untersuchen war auch, welche Auswirkungen es auf das Verhalten hat, wenn ein appetitiver oder ein aversiver Reiz vor dem Verhalten vorhanden ist, aber durch das Verhalten beendet wird. Die sich hieraus ergebenden weiteren drei Möglichkeiten, zu denen Versuche gemacht werden mussten, gibt die folgende Tabelle wieder und werden der Reihe nach erläutert:
| Auf das Verhalten folgender Reiz... | ...ist unangenehm/aversiv (Strom im Boden der Skinner-Box) | ...ist angenehm/appetitiv (Futtergabe) |
| ...endet oder beginnt erst gar nicht | 1 | 2 |
| ...beginnt | 3 |
positve Verstärkung |
Da Skinner bei seinen Versuchen zur positiven Verstärkung auch sofort geprüft hat, ob und wie der Prozess der Löschung verläuft, wenn die Verstärkung nicht mehr in Folge des Verhaltens gegeben wird, stellt sich sofort eine weitere Frage: Wie wird sich die unterschiedliche Verwendung appetitiver und aversiver Reize auf die bei der positiven Verstärkung beobachtete Löschung auswirken?
Der Versuchsaufbau: Adaptionen der Skinner Box
Leider ist nicht jeder Versuch oder jede Versuchsreihe, die Skinner durchführte, heute einfach recherchierbar. Jedoch zeigen die Inhalte der von Skinner und seinem Wissenschaftlerteam entwickelten operanten Konditionierung, welche Art von Versuchen sie durchgeführt haben müssen.
Um Versuche mit aversiven Reizen durchführen zu können, musste Skinner seine Box so adaptieren, dass sie einen solchen Reiz zur Verfügung stellen kann. Er versieht sie daher zusätzlich mit einem metallenen Boden, der elektrischen Strom leiten kann. Er tat dies in der Annahme, dass der leichte elektrische Strom als unangenehm und damit aversiv empfunden werden wird.
Da es andererseits auch darum geht, Reize in einer Versuchsreihe durch ein Verhalten enden zu lassen, während sie in einer anderen Versuchsreihe durch das Verhalten beginnen, wurden die Boxen so verdrahtet, dass die Reize entweder durch ein Verhalten ausgelöst oder beendet wurden. Im Folgenden werden wir uns die denkbaren Versuche im Einzelnen ansehen.
Wie liefen die Versuche Skinners zu negativer Verstärkung ab?
| Auf das Verhalten folgender Reiz... | ...ist unangenehm/aversiv (Strom im Boden der Skinner-Box) | ...ist angenehm/appetitiv (Futtergabe) |
| ...endet oder beginnt erst gar nicht | negative Verstärkung | 2 |
| ...beginnt | 3 | positve Verstärkung |
Auf das Verhalten folgender Reiz...Um die Auswirkung des Wegfalls eines unangenehmen Reizes auf das Verhalten im Experiment zu ergründen, wurden einerseits die Tauben verwendet, die zuvor für die Experimente zur positiven Verstärkung eingesetzt wurden und deren konditioniertes Verhalten gelöscht war. Eine zweite Gruppe hatte noch an keinen Experimenten teilgenommen und ist noch nie darauf konditioniert worden, auf die Schaltfläche zu picken. Genau wie schon bei den Versuchen zur positiven Verstärkung, wurden in einem ersten Schritt die Versuchstauben in die Box gesetzt, ohne, dass irgendwelche weiteren Reize verabreicht wurden, um so die Baseline des Verhaltens zu ermitteln.
Im zweiten Schritt wurde die Skinner Box so konfiguriert, dass im Boden ein leichter, aber dennoch unangenehmer und damit als aversiver Reiz empfundener Strom floss. Dieser konnte von dem Versuchstier durch ein bestimmtes Verhalten, beispielsweise durch das Picken einer Taube auf die uns schon bekannte Schaltfläche, abgeschaltet werden, um dann nach einiger Zeit, beispielsweise 10 Sekunden, wieder automatisch eingeschaltet zu werden.
Entsprechend der aktuellen Erkenntnisse und Theorien wurden dabei wohl zwei unterschiedliche Auswirkungen dokumentiert. Bei einem Teil der Tiere kam es scheinbar dazu, dass die Auftrittswahrscheinlichkeit des Verhaltens „Picken auf die Schaltfläche“ der Tiere anstieg, um den Strom abzuschalten. Sicherlich konnte auch dokumentiert werden, dass diese Tiere kurz vor dem automatischen Einschalten des Stroms vermehrt auf die Scheibe pickten und so verhinderten, dass er wieder zu fließen begann.
Ein anderer Teil der Tiere fand aber keinen Zusammenhang zwischen dem Picken auf die Schaltfläche und dem Abstellen des Stromes. Diese Tiere zeigten unterschiedliche Arten teilnahmslosen, inaktiven Verhaltens. Bei dieser Gruppe hatte also die negative Konditionierung nicht funktioniert.
Der Anteil derer, die erfolgreich negativ konditioniert werden konnte, lag wahrscheinlich in der Gruppe, die vorher schon einmal positiv auf das Picken der Schaltfläche konditioniert wurde, höher, als bei denen, die noch keine Erfahrung mit der Schaltfläche gemacht hatten.
Im dritten Schritt, bei dem die Konfiguration der Box wieder der stromfreien im ersten Schritt entsprach, sollte nun festgestellt werden, ob die Auftrittswahrscheinlichkeit des konfigurierten Verhaltens nun wieder sinkt und das Verhalten gelöscht wird. Es stellte sich heraus, dass die Effekte der Löschung bei den erfolgreich Konditionierten viel geringer waren, als es bei der positiven Verstärkung der Fall war.
Wie liefen die Versuche Skinners zu negativer Bestrafung ab?
| Auf das Verhalten folgender Reiz... | ...ist unangenehm/aversiv (Strom im Boden der Skinner-Box) | ...ist angenehm/appetitiv (Futtergabe) |
| ...endet oder beginnt erst gar nicht | negative Verstärkung | negative Bestrafung |
| ...beginnt | 3 | positve Verstärkung |
Wie ein Experiment Skinners zur negativen Bestrafung aufgebaut war, war weder recherchierbar, noch fühle ich mich befähigt, es aus den Theorien und überlieferten Experimenten Skinners abzuleiten. Mir möchte kein Weg einfallen, wie die Skinner Box aufgebaut sein muss, dass sie automatisch einen angenehmen Reiz (beispielsweise Futter) entfernt, wenn ein bestimmtes Verhalten gezeigt wird: So lange einer auf 80 % abgemagerten Taube Futter dargereicht wird, wird sie fressen und kein anderes Verhalten zeigen. Das Fressen wiederum kann aber kaum durch Entfernen des Futters (angenehmer Reiz) bestraft werden.
Wäre die Taube später satt und würde deshalb auch anderes Verhalten zeigen, das bestraft werden könnte, stellt sich die Frage, ob das Futter dann noch einen angenehmen Reiz darstellen würde, dessen Entfernung tatsächlich das Verhalten der Taube beeinflussen würde, da sie sich ja in ihrem satten Zustand weniger für das Futter interessiert.
Außerhalb des Tierexperiments, beispielsweise im Straßenverkehr, wird aber schnell klar, was gemeint ist: Der Führerschein und damit die Erlaubnis, Auto zu fahren, stellt den angenehmen Reiz dar. Betrunkenes oder zu schnelles Fahren ist das Verhalten, dass es zu minimieren gilt. Die negative Strafe wäre dann der Entzug des Führerscheins.
Allerdings beobachten wir, dass häufig trotzdem die Verkehrsregeln gebrochen werden und erst beim Anblick einer Geschwindigkeitskontrolle stark gebremst wird. Warum das so ist, hat Skinner wieder belegbar ergründet, wie wir sehen werde, wenn wir uns im Anschluss an das Kontingenzschema mit den Hinweisreizen beschäftigen.
Wie liefen die Versuche Skinners zu positiver Bestrafung ab?
| Auf das Verhalten folgender Reiz... | ...ist unangenehm/aversiv (Strom im Boden der Skinner-Box) | ...ist angenehm/appetitiv (Futtergabe) |
| ...endet oder beginnt erst gar nicht | negative Verstärkung | negative Bestrafung |
| ...beginnt | positive Bestrafung | positve Verstärkung |
Versuche zur positiven Bestrafung sind überliefert.
Um die Auswirkung eines unangenehmen Reizes auf das ihm vorangehende Verhalten zu erforschen, wurde die Box nun so verdrahtet, dass das Picken auf die Schaltfläche einen leichten, aber sicher als aversiv empfundenen Stromstoß im Boden der Box auslöste.
Nun wurden einige Tauben über positive Konditionierung trainiert, auf die Schaltfläche zu picken und dann in zwei Gruppen aufgeteilt. Einer Gruppe wurde in den folgenden Sitzungen das Picken auf die Schaltfläche nicht verstärkt, es erfolgte also eine Löschung. Die andere Gruppe wurde für das Picken auf den Schalter bestraft, indem ihnen ein leichter Stromstoß als aversiver Reiz über den Fußboden verabreicht wurde.
Gemessen und miteinander vergleichen wurde für beide Gruppen die Reaktionsrate im Zeitverlauf. Im Ergebnis verringerte sich die Reaktionsrate der bestraften Tauben im Vergleich zur lediglich in der Löschungsphase befindlichen Tauben zunächst signifikant.
In einer letzten Experimentphase wurde nun beide Gruppen wie in einer Löschung behandelt: Das Picken wurde weder verstärkt, noch bestraft.
Nun wurde erkennbar, dass in der Gruppe, die vorher Bestrafung erfuhr, die Reaktionsrate nun, da keine Bestrafung mehr erfolgte, zunächst zunahm und sich dann so weiterentwickelte, also abnahm, wie es unter der Bedingung der Löschung zu erwarten war.
Im Ergebnis war bei beiden Gruppen die Reaktionsrate nach einiger Zeit auf demselben Niveau angekommen.
Welche Schlüsse zog Skinner aus diesen Versuchen: Das Kontingenzschema
Ähnlich, wie schon bei der positiven Konditionierung, definierte Skinner auch zu den drei weiteren Varianten die Begrifflichkeiten.
Für die negative Konditionierung sieht das folgender Maßen aus: Der aversive (unangenehme) Reiz, der von dem im Boden fließenden Strom ausgeht, wurde von Skinner „negativer Verstärker“ genannt. Hierbei ist wichtig, dass ein aversiver Reiz immer nur dann ein Verstärker ist, wenn das seinem Wegfall vorangegangene Verhalten so beeinflusst wird, dass es künftig häufiger gezeigt wird, also die Auftrittswahrscheinlichkeit des Verhaltens steigt. Negativ wird der Reiz dadurch, dass er nach dem Verhalten entfällt oder endet. Durch negative Konditionierung kann Vermeidungsverhalten aufgebaut werden. Es führt dazu, dass der negative Reiz durch frühzeitige, die Situation vermeidende Reaktionen wie Flucht gar nicht erst auftritt. Dies führt wiederum dazu, dass der negative Reiz erst gar nicht entsteht und wahrgenommen werden kann. Da aber die Situation gemieden wird, kann auch nicht wahrgenommen werden, ob der negative Reiz unabhängig vom Verhalten gar nicht mehr auftritt. Diese Wirkungskette begründet die hohe Widerstandsfähigkeit des über negative Konditionierung aufgebauten Verhaltens gegenüber der Löschung.
Hiervon zu unterscheiden ist die negative Bestrafung, die auf die Verringerung einer unerwünschten Verhaltensweise zielt: Wird das unerwünschte Verhalten gezeigt, wird ein grundsätzlich vorhandener, als Verstärker dienender appetitiver/angenehmer Reiz entfernt (negiert).
Die positive Strafe zeichnet sich dadurch aus, dass der unangenehme Reiz als Folge unerwünschten Verhaltens auftritt. Gegenüber der Löschung scheint sie kurzfristig schneller zum Erfolg zu führen. Allerdings holt die Löschung im Zeitverlauf den Vorsprung der Strafe auf, was aber nur dann möglich ist, wenn die Verhaltensverstärker unter kontrollierbar sind und nicht mehr in Folge des zu löschenden Verhaltens verfügbar werden.
So wird klar, dass die Begriffe „positiv“ und „negativ“ keine Wertung enthalten, sondern lediglich ausdrücken, ob ein Reiz in Folge eines Verhaltens gegeben wird (positiv) oder entzogen bzw. negiert (negativ) wird.
Skinner fasste die drei zu einem Kontingenzschema zusammen, aus dem hervorgeht, welche Reize mit welcher Verhaltensänderung einhergehen. Aus dem Schema geht nicht nur die enge Verbundenheit von Reizen und Verhalten hervor, sondern auch, dass er die Begriffe „Verstärker“ und „Bestrafung“ nur auf Grund ihrer beobachteten Auswirkung auf das operante Verhalten definiert sind. Daher lässt sich vor Beginn des Experiments oder der Ausbildung bestenfalls abschätzen, nicht aber mit Sicherheit wissen, wie ein Reiz wirken wird.
| Auf das Verhalten folgender Reiz | Auftrittswahrscheinlichkeit des Verhaltens steigt | Auftrittswahrscheinlichkeit des Verhaltens sinkt |
| beginnt | positive Verstärkung | positive Bestrafung |
| endet oder beginnt erst gar nicht | negative Verstärkung | negative Bestrafung |
Welche Fragen stellten sich aus Skinners Versuchen zum Kontingenzschema?
In den Experimenten hatte sich gezeigt, dass Verhalten nur über positive und negative Verstärkung aufgebaut werden kann, während positive und negative Strafen nur dazu dienen können, ein Verhalten abzubauen. Sie dienen aber insbesondere nicht dazu, ein geeignetes Alternativverhalten aufzubauen und lassen den Bestraften insofern etwas ratlos zurück. Skinner schloss außerdem aus seinen Ergebnissen zur positiven Bestrafung, dass Bestrafung ineffektiv sei. Dem schlossen sich nicht alle folgenden Wissenschaftler an, sodass wir uns mit der Forschung zu Bestrafungen in Block 8 diese Artikels noch intensiv befassen werden.
Bewertet man nun die positive und negative Verstärkung, stellt man fest, dass das aufgebaute Verhalten bei der positiven Konditionierung sehr schnell wieder gelöscht wird, wenn die Verstärkung ausbleibt. Wird nur der Aspekt der Dauerhaftigkeit eines konditionierten Verhaltens betrachtet, könnte man schnell auf die Idee kommen, dass die negative Verstärkung das Mittel der Wahl ist. Jedoch würde dann übersehen, dass ein erheblicher Teil der Versuchstiere bei der negativen Konditionierung das erforderliche Verhalten nicht gelernt hat, sondern nur uneffektives Verhalten gezeigt hat und schließlich in einen teilnahmslosen, apathischen Zustand verfallen ist, der sogenannten und unten in Block 8 behandelten gelernten Hilflosigkeit.
Skinner war außerdem der Meinung, dass außerhalb des Labors Verhalten nicht in derart gleichmäßiger und vorhersehbarer Art und Weise verstärkt wird: Beispielsweise führt nicht jede Jagd eines Beutegreifers auch zu Beute oder jedes Spiel an einem Automaten zu einem Gewinn. Dennoch kann klar beobachtet werden, dass Raubtiere immer wieder jagen und einige Menschen immer wieder ihr Glück am Spieltisch versuchen.
Diese Tatsache weckte Skinners Interesse an Versuchen zu Verstärkerplänen. Außerdem stellte sich die Frage, ob solche Verstärkerpläne Auswirkungen auf die Konditionierungsgeschwindigkeit und die Löschungsresistenz bei positiver Verstärkung haben. Diesem Themenkomplex ist mit dem nächsten Block dieses Textes ebenfalls ein großer Abschnitt gewidmet.
Ebenfalls war ihm nun zwar klar, dass die Auswirkungen von Verhalten dasselbe beeinflussen. Der bisherige Versuchsaufbau lässt aber außer Acht, ob und wie Verhaltens situationsabhängig gezeigt werden kann. Die Reize, die eine Situation ausmachen, nannte Skinner „diskriminative“ Reize.
Die Forschung Skinners zu diskriminativen Reizen – mehr als Kommandos
Widmen wir uns aber zunächst Skinners Frage nach situationsabhängigem Verhalten.
Skinners Forschungsziel – Wie adaptieren Organismen ihr Verhalten in unterschiedlichen Situationen?
Als Skinner das Kontingenzschema unter Ausschluss aller anderen Umwelteinflüsse in seinen Skinner Boxen erforschte, war ihm klar, dass außerhalb dieser sterilen Laborbedingungen weitere als Reize wahrgenommene Umwelteinflüsse auf das Verhalten eines Lebewesens wirkt. So ist ihm klar, dass beispielsweise trotz Strafbewehrung gegen Verbote verstoßen wird. Auch konnte er schon damals beobachten, dass ein Hund vor allen Dingen nach einem Kommando Sitz machte und nicht immer und ewig in der entsprechenden Haltung verharrt. Die hier genannten Reize definieren in ihrer Summe die Situation, in der ein bestimmtes Verhalten gezeigt oder vermieden wird.
Der Versuchsaufbau: Erweiterung der Skinner Box um einen diskriminativen Reiz
Nachdem die Tauben im oben beschriebenen Experiment zur positiven Verstärkung gelernt hatten, mittels Picken auf einen Knopf den Futterspender auszulösen, wurde die Skinner Box mit einer Lampe und/oder einem Lautsprecher ausgestattet. Nun wurde die gesamte Technik so verdrahtet, dass der Futterspender nur dann ausgelöst werden konnte, wenn entweder das Licht brannte oder der Ton zu vernehmen war. Allerdings wurde darauf geachtet, dass der Effekt der Löschung nicht eintreten konnte, von dem Skinner schon wusste, in welchem zeitlichen Fenster dieser einsetzen würde. Entsprechend wurde darauf geachtet, dass Licht oder Ton und damit die Futtergabe früh genug gegeben war und die Frequenz zwischen an und aus hoch genug war, damit eben keine Löschung erfolgte.
Um die Versuche zur positiven Bestrafung um einen diskriminativen Reiz zu erweitern, wurde der aus der positiven Verstärkung bekannte Versuchsaufbau, in dem das Picken auf einen Schalter eine Verstärkung durch Futter brachte, so abgeändert, dass der einer zu bestrafenden Verhaltensweise folgende unangenehme Reiz nicht mehr automatisch, sondern von einem Menschen mittels Knopfdruck verabreicht wurde. Konkret stand also dieser Labormitarbeiter mit einer Fernbedienung vor der in beide Richtungen durchsichtigen Skinner-Box. Somit konnte er von dem Versuchstier gesehen und beobachtet werden, wenn der mittels Knopfdruck in den Boden der Skinner Box einen kurzen Stromstoß sandte.
Versuche zu diskriminativen Reizen – die Einführung von Hinweisreizen in der positiven Verstärkung
Nun konnten die Forscher messen, dass die Tauben zu Beginn dieses Experiments das erlernte Verhalten zeigten: Sie pickten immer weiter auf den Auslöser.
Bald schon ergaben die Messungen, dass die Tauben nur noch sehr selten den Auslöser betätigten, wenn kein zusätzliches Signal gegeben wurde, aber sehr viel häufiger, wenn es gegeben wurde.
Damit hatten die Tiere gelernt, das Licht oder den Ton als diskiriminativen Reiz oder als Hinweisreiz zu deuten, der anzeigt, wann ein bestimmtes Verhalten zu einer angenehmen Konsequenz führt und daher lohnenswert ist und wann das Verhalten nicht lohnenswert ist, da eben kein positiver Verstärker folgt.
Versuche zu diskriminativen Reizen – die Wirkung von Hinweisreizen bei Strafandrohungen
Es wurden nun Versuchstiere, die über die positive Verstärkung bereits so konditioniert wurde, dass sie auf den Schalter picken, um Futter zu erhalten, in die Skinner-Box gesetzt. Dort verhielten sie sich entsprechend der Konditionierung und pickten häufig auf die Schaltfläche und erhielten weiterhin Futter.
Nach einiger Zeit trat jedoch der Versuchsleiter an die Box und nahm die Fernbedienung in die Hand, um auf jedes Picken hin einen kurzen Stromstoß in den Boden der Skinner Box zu leiten, bevor das Tier an das immer noch ausgelöste Futter gelangen konnte. Nach einigen Durchläufen aus Picken und Stromstoß legte der Laborant den Auslöser aus der Hand und entfernte sich von der Box.
Zu beobachten war nun, dass die Versuchstiere nach einigen wenigen Durchgängen die Anwesenheit des Laboranten als Hinweisreiz wahrnahmen: Ist er anwesend, folgt dem Verhalten ein aversiver und damit strafender Reiz und das Picken auf die Schaltfläche wurde eingestellt. War er nicht zu sehen, wurde intensiv gepickt, da dann dem Verhalten ein angenehmer Reiz folgte: nämlich das Erreichen und Fressen des Futters.
Welche Schlüsse und Fragen ergaben sich aus den Versuchen zu den Hinweisreizen?
Bezogen auf die positive Konditionierung ergibt sich der Schluss, dass der Hinweisreiz ein Verhalten auslösen kann, da der diskriminative Reiz darauf hinweist, dass dem entsprechenden Verhalten ein angenehmer Reiz folgen wird. Aus diesem Grund lohnt es sich für den Organismus, dieses Verhalten in Folge des Hinweisreizes zu zeigen. Da das von Skinner entwickelte Reaktion-Reiz-Modell nun um ein weiteres Element zu einem Reiz-Reaktion-Reiz-Modell erweitert wurde, spricht man nun von der Dreifachkontingenz aus Hinweisreiz, operanten Reaktion und Verstärkung/Verstärkungsreiz, wobei jedes Kettenglied für das folgende eine hohe Vorhersagekraft besitzt.
Bezogen auf die Versuche zur Bestrafung lassen sich aus der Beobachtung, dass das unter Strafe stehende Verhalten nur dann nicht mehr gezeigt wird, wenn der strafende Labormitarbeiter anwesend war, zwei Schlussfolgerungen ziehen. Einerseits, dass die Anwesenheit des Labormitarbeiters für die Tiere zum Hinweisreiz eines ihrem Verhalten folgenden aversiven Reizes, also der Strafe ist. Andererseits, dass eine Strafe nicht zu einer Verhaltenslöschung oder einer nachhaltigen Verhaltensänderung führt, sondern lediglich zu einer Verhaltensunterdrückung in Erwartung der Strafe. Wird auf Grund eines Hinweisreizes wie der Abwesenheit des Labormitarbeiters Straffreiheit erwartet, tritt das Verhalten wieder auf.
Die Forschung Skinners & seiner Nachfolger zu Verstärkerplänen
Der Hund soll nicht alles nur für Futter und Belohnung tun! Das hört man häufig und es stimmt nicht nur, sondern weniger Belohnen kann sogar ein Verhalten weiter festigen. Wie das geht, zeigt Skinners Forschung zu Verstärkerplänen.
Was sind Verstärkerpläne?
Wie für die operante Konditionierung insgesamt, so legte Skinner auch den Grundstein für die Erforschung von Verstärkerplänen. Hierbei handelt es sich um Regeln, die festlegen, wann ein gewünschtes oder zu konditionierendes Verhalten verstärkt wird. Wir werden uns hier mit den vier „einfachen“ Verstärkerplänen beschäftigen, die von Skinner zunächst miteinander verglichen wurden. Zu diesen vier Verstärkungsplänen gibt es schon viel zu sagen und vor allem begründen die Beobachtungen einige Fragen. Diese zu beantworten war für die Wissenschaft nicht einfach, weshalb die Antworten zu liefern entsprechend lange dauerte und Teil der Arbeit anderer Forscher war.
Skinners Forschungsziel – Die Auswirkungen unregelmäßiger Verstärkungen
Skinner fragte sich, wie wir im Abschnitt zum Kontingenzschema gesehen haben, ob die Tatsache, dass im Leben außerhalb des Labors Verhalten nicht jedes Mal, sondern eher in unregelmäßiger Art und Weise verstärkt wird, im Labor nachgestellt werden kann und welche Auswirkungen es haben würde, wenn die Vorhersagekraft, die ein Verhalten auf die Verstärkung hat, herabgesetzt wird.
Wir haben gesehen, dass zwar ein Verhalten schnell über die positive Verstärkung konditioniert werden kann, aber auch sehr schnell nicht mehr gezeigt wird und somit gelöscht wird, wenn keine Verstärkung mehr erfolgt. Als Alternative, ein Verhalten so zu festigen, dass es auch ohne weitere Verstärkung gezeigt wird, steht zu diesem Zeitpunkt nur die negative Verstärkung zur Verfügung. Diese birgt aber offenbar das Problem, dass sie nicht zu 100 Prozent erfolgreich verläuft, sondern ein Teil der Tiere in Apathie verfallen, statt das gewünschte Verhalten zu zeigen.
Skinners Frage war nun, ob und welche Auswirkung auf die Aquisitionsrate, die die Konditionierungsgeschwindigkeit beschreibt, und Extinktionsrate, die die Widerstandsfähigkeit gegen Löschung beschreibt, es hat, wenn Verstärkung bei der positiven Konditionierung nicht jedes Mal erfolgt, wenn das zu konditionierende Verhalten gezeigt wird. Die unterschiedlichen Regeln, nach denen die Verstärker gegeben werden können, nennt man Verstärker- oder Verstärkungspläne.
Der Versuchsaufbau: Adaptionen der Skinner Box für verschiedene Verstärkerpläne

Skinner war sich bewusst, dass es im realen Leben Verhalten gibt, das nicht jedes Mal zu einer Verstärkung führt. Außerdem war ihm klar, dass es zwei Größen gibt, die eine Auswirkung auf die Verstärkung haben: Die Anzahl der Wiederholungen eines Verhaltens einerseits und der Zeitpunkt, an dem das Verhalten gezeigt wird, andererseits.
Nimmt man an, dass ein Fuchs oder ein Hund 10 Versuche braucht, um einen Hasen zu fangen, wäre das ein auf der Anzahl der Wiederholungen des Verhaltens „hinter dem Hasen herlaufen“ basierender Verstärkungsplan, den Skinner Ratio-Plan, also Quotenplan, nannte. Sicherlich wäre es nicht so, dass der Jagderfolg immer den exakt jeden 10. Hasen treffen würde. Wäre es so, spräche Skinner von einem fixed Ratio Plan und wir in Deutschland von einem festen Quotenplan. Realistischer beschrieben wäre unser Beispiel, wenn mal zwei Jagden hintereinander erfolgreich und dann wieder 20 oder 30 Anläufe hintereinander erfolglos blieben, im Durchschnitt aber 1 von 10 Versuchen Erfolg brächten. In dem Fall wäre in den USA von einem variable Ratio Plan und bei uns von einem variablen Quotenplan die Rede.
Nimmt man an, dass ein Fuchsliebhaber im Wald eine Fütterung für den Fuchs einrichtet und jeden Tag um 12:00 Uhr dort etwas Futter für das Tier bereitstellt. Das Verhalten „die Futterstelle aufsuchen“ kann zwar unendlich oft am Tag gezeigt werden. Verstärkt wird es aber nur einmal in 24 Stunden. Somit spielt die Anzahl der Verhaltenswiederholungen keine, das richtige Timing aber eine große Rolle. In dem Fall sprechen wir über einen Intervallplan. Da das Intervall exakt feststeht, nämlich alle 24 Stunden, wird hier von einem fixed Interval Plan oder einem festen Intervallplan gesprochen. Würde der Fuchsliebhaber nicht immer pünktlich, aber auf jeden Fall einmal innerhalb von 24 Stunden die Fütterung bestücken, läge ein variable Interval Plan oder variabler Intervallplan vor.
Skinner versuchte nun, wie im Folgenden beschrieben, seine in den Versuchen zur positiven Verstärkung genutzten Skinner Boxen so umzurüsten, dass sie jeweils einen der vier beschriebenen Verstärkungspläne nachstellen und die Auswirkungen dokumentieren konnten.
Adaption der Skinner Box für Fixed Ratio bzw. feste Quotenpläne
In einer Variante sollten Ratio- bzw. Quotenpläne erforscht werden, es ging also um die Anzahl der Wiederholungen eines Verhaltens. Ausgehend von der Immerverstärkung, bei der nach jeder gewünschten Reaktion einer Verstärkung erfolgt, wurde der schon vorhandene Zählmechanismus so verdrahtet, dass der Versuchsleiter die für eine Verstärkung notwendige Anzahl an Verhaltenswiederholungen einstellen konnte. Hierbei sprach Skinner von einem „fixed ratio plan“, der in Deutsch fixer Quotenplan genannt wird. Insofern kann man die Immerverstärkung als einen fixen Quotenplan mit der Ziffer 1 (FR-1-Plan) betrachten. Allerdings wird im Allgemeinen erst dann von einem fixen Quotenplan gesprochen, wenn die Ziffer und damit die Quote höher als 1 ist, beispielsweise FR-2-Plan, bei dem jede 2. zu konditionierende Reaktion verstärkt wird.
Adaption der Skinner Box für Variable Ratio bzw. variable Quotenpläne
Die Box konnte aber auch so eingestellt werden, dass der Zählmechanismus eine vorher festgelegte Anzahl von Verstärkungen auf eine ebenfalls vorher festgelegte Gesamtmenge Wiederholungen unregelmäßig verteilt. Wichtig ist, dass ein Durchschnittswert von Wiederholungen für eine Verstärkung definiert war. Wird also nur eine Durchschnittsquote definiert, sprach Skinner von einem „variable ratio plan“ und die deutschen Wissenschaftler von einem variablen Quotenplan. Einen Verstärkerplan nach dem Schema der Immerverstärkung könnten man als einen VR-1-Plan bezeichnen. Üblich sind allerdings Pläne, bei denen die Quote höher ist, also ab einem VR-2-Plan. Ein VR-2-Plan sähe also vor, dass auf 10 korrekte Verhaltensweisen 5 Verstärkungen, auf 100 Verhaltensweisen 50 Verstärkungen kämen. Dabei wäre es dann möglich, dass auf die ersten 5 Wiederholungen keine Verstärkung erfolgt, dafür aber die letzten 5 alle verstärkt würden.
Adaption der Skinner Box für feste und variable Intervallpläne
In der zweiten Variante wurden Intervallpläne erforscht. Es wurde eine Art Wecker eingebaut, damit die Verstärkung zeitabhängig gegeben werden konnte. Der Wecker konnte so eingestellt werden, dass er, statt zu klingeln, einen Stromkreis schloss. Dadurch löste das nächste gewünschte Verhalten, beispielsweise das Picken auf die Schaltfläche, eine Verstärkung aus. Der Wecker konnte nun für eine Versuchsgruppe so eingestellt werden, dass er nach einer festen Zeitspanne, z. B. alle 5 Minuten, das Verstärkungssystem einschaltete. In dem Fall spricht man von einem fixen Intervallplan, Skinner von einem „fixed interval plan“. Für die andere Versuchsgruppe konnte er aber auch so eingestellt werden, dass er in einer festgelegten Gesamtzeitspanne in unregelmäßigen Zeitabständen das Verstärkungssystem einschaltete, dass im Durchschnitt ein vorher festgelegter Zeitintervall eingehalten wurde. So könnte eine Regel konkret lauten, dass das Verstärkersystem in unregelmäßigen Abständen 12 Mal pro Stunde frei geschaltet werden soll. 60 Minuten geteilt durch 12 Freischaltungen ergibt im Durchschnitt wieder eine Freischaltung alle 5 Minuten. Hierbei handelt es sich um eine variablen Intervallplan.
Wie liefen die Versuche Skinners zu Verstärkungsplänen ab?
Für alle Experimente zu den verschiedenen Verstärkerplänen wurde ähnlich verfahren, wie schon in den ursprünglichen Versuchen zur positiven Verstärkung: Versuchstiere, die noch nie in der Skinner Box gesessen hatten, bekamen im Vorfeld der Experimente freien Zugang zu Futter und Wasser. Sie wurden täglich gewogen, um ihr Normalgewicht zu ermitteln. Dann wurde der Zugang zu Futter begrenzt, sodass sie nach einigen Tagen auf 80 % ihres Normalgewichts kamen. Damit sollte sichergestellt werden, dass die Verfügbarkeit von Futter als angenehm empfunden wird und die Gabe von Futter als Konsequenz eines Verhaltens verhaltensverstärkend wirkt.
In der Kontrollphase all dieser Experimente wurden nun die Tiere einzeln in eine Skinner Box gesetzt, ohne, dass das Picken auf die Schaltfläche eine Futtergabe auslöste. So wurde gemessen, wie häufig ein Tier vor der Konditionierung in einer bestimmten Zeitspanne auf die Schaltfläche pickt, es wurde also die Basisreaktionsrate des gewünschten Verhaltens und damit die Auftrittswahrscheinlichkeit des Pickens auf die Schaltfläche für jedes einzelne Tier gemessen.
Nun wurden die Tiere für Akquisitionsphase und die Löschungsphase in vier Gruppen aufgeteilt, damit für den festen Quotenplan, den variablen Quotenplan, den festen Intervallplan und den variablen Intervallplan jeweils ein Anzahl Probanden zur Verfügung stand.
Die Versuche zu Quotenplänen
Eine Gruppe von Probanden kam nun in eine Box, die nach einer festen Anzahl an Wiederholungen eine Verstärkung auslöste, die andere Gruppe in eine Box, die unregelmäßig nach festgelegten Durchschnittwerten verstärkte. Natürlich wurden viele Versuchsreihen unternommen, in denen die Anzahl der regelmäßig oder durchschnittlich bis zur Auslösung einer Verstärkung notwendigen Wiederholungen des Pickens auf die Schaltfläche variiert wurde.
Während der Akquisitionsphase, in der ein bestimmtes Verhalten erworben oder konditioniert wird und in der die Reaktionsrate folglich zunimmt, wurde sowohl für die fixe wie für die variable Quotenverstärkung beobachtet, dass die Akquisitionsrate, mit der die Geschwindigkeit des Verhaltenserwerbs ausgedrückt wird, umso niedriger ist, je höher die Quoten sind: Je öfter das gewünschte Verhalten vor der Gabe einer Verstärkung gezeigt werden muss, desto langsamer verläuft der Verhaltenserwerb.
Außerdem zeigte sich, dass von Tieren, die nach festen Quotenplänen trainiert wurden, nach jeder Verstärkung für einige Zeit eine Pause eingelegt wurde, in der sie das konditionierte Verhalten nicht zeigten und die abrupt endete. Hierfür wurde der Begriff der Nachverstärkerpause geprägt, die bei variablen Quotenplänen nicht beobachtet wurde, sodass die variablen Quotenplänen eine kontinuierlichere Reaktionsrate zeigten.
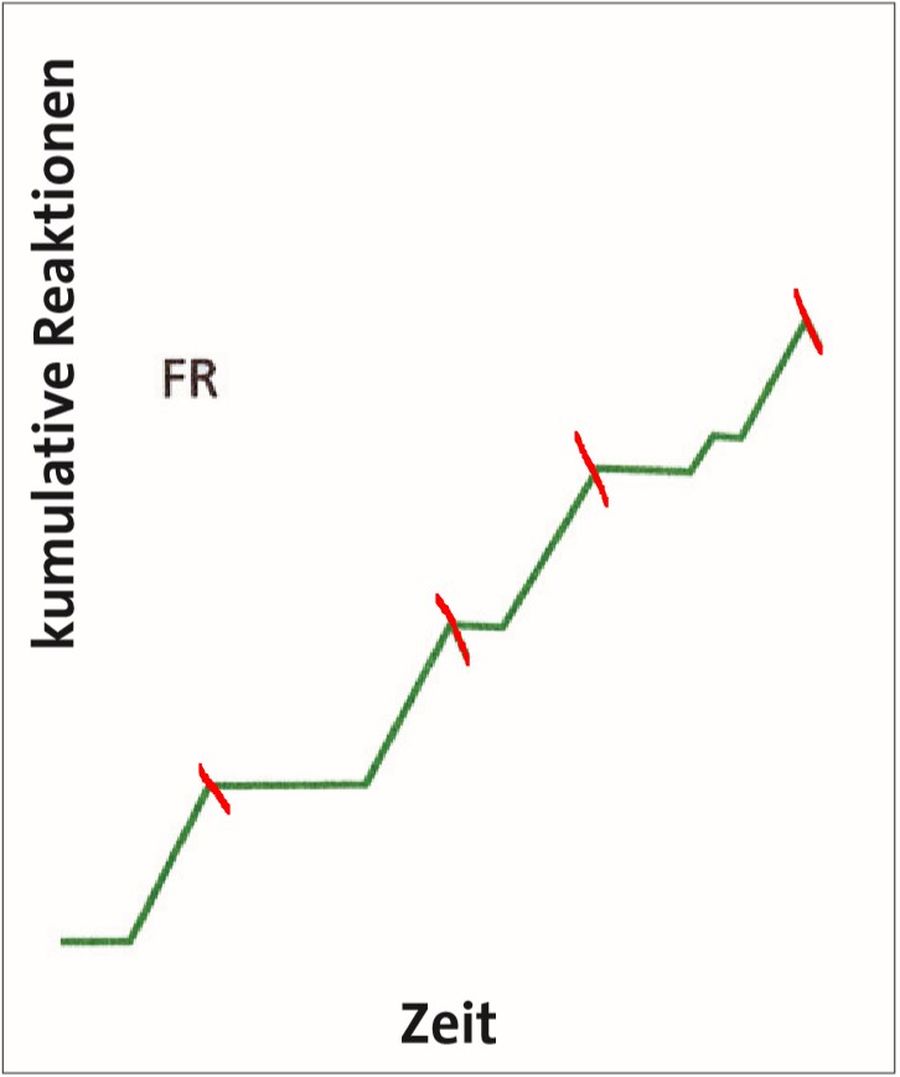
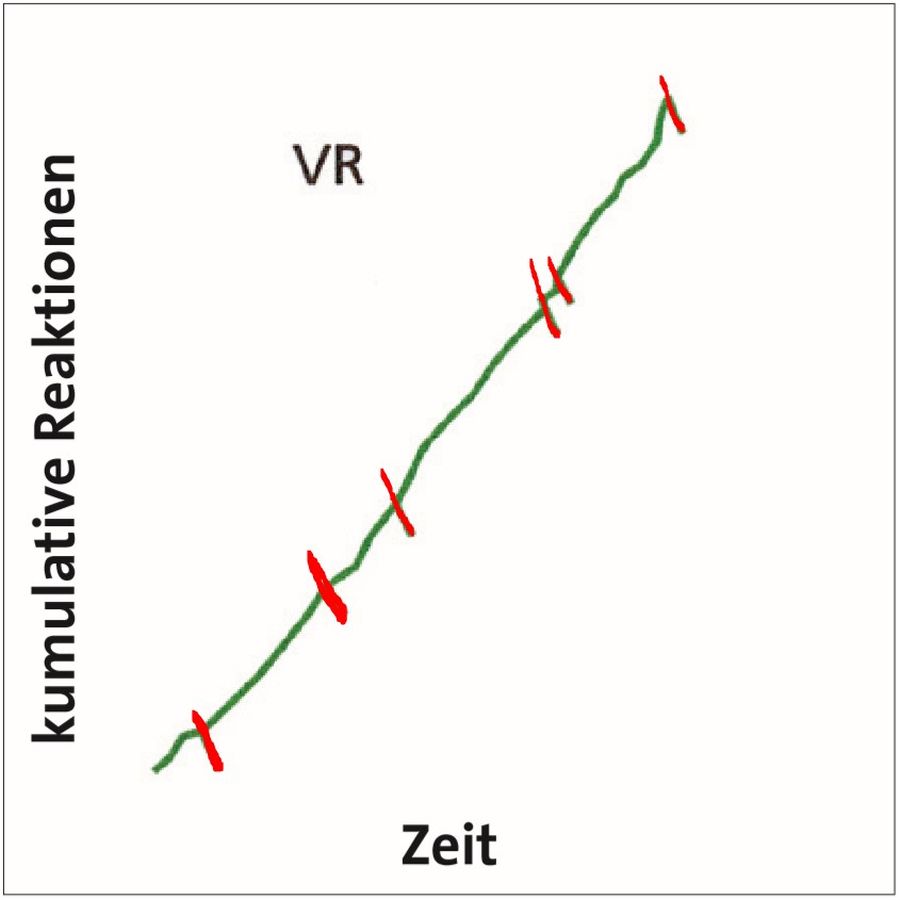
In der Löschungsphase, in der keine Verstärkung mehr erfolgt, wird die Extinktionsrate, also die Geschwindigkeit, mit der Reaktionsrate abnimmt gemessen. Hierbei wurde festgestellt, dass die Löschungsresistenz des konditionierten Verhaltens desto höher ausfällt, je höher die Quote, egal ob fix oder variabel, in der Akquisitionsphase gewählt war.
Die Versuche zu Intervallplänen
Ähnlich verfuhr er auch für die Versuche zur Intervallverstärkung, bei der zwischen den einzelnen Verstärkungen eine zeitliche Pause, ein Intervall liegt. In der Box für die eine Gruppe wurde nach einer immer gleichlangen Pause, also nach fixen Intervallen, dem sogenannten FI-Plan, verstärkt. In der anderen Box wurde nach dem VI-Plan verstärkt. Es wurde also nur die durchschnittliche Länge des Intervalls festgelegt, allerdings konnte jedes Intervall von diesem Durchschnittswert abweichen und viel kürzer oder auch länger dauern.
Auch bei den Intervallplänen zeigte sich, dass die Akquisitionsrate desto niedriger war, je länger die Intervalle gewählt waren.
Und, ähnlich wie bei den fixen Quotenplänen, zeigten sich auch bei den fixen Intervallplänen kein gleichmäßiger Verlauf der Reaktionskurve: Nachdem eine Verstärkung erfolgte, ging die Reaktionsrate stark herab und wuchs bis zum Zeitpunkt der nächsten Verstärkung stark an. Es wird als mit wenigen Reaktionen pro Minute wieder begonnen und kurz vor der nächsten Verstärkung weit mehr Reaktionen pro Minute gezeigt. Auf diese Weise entsteht im Diagramm der sogenannte FI-Bogen.
Bei den variablen Intervallplänen zeigten sich keine Nachverstärkerpausen, sondern wieder eine sehr kontinuierliche Reaktionsrate.
Zur Erinnerung: Bei der Reaktion kann es sich um das Picken auf den futterauslösenden Schalter durch die Tauben handeln.
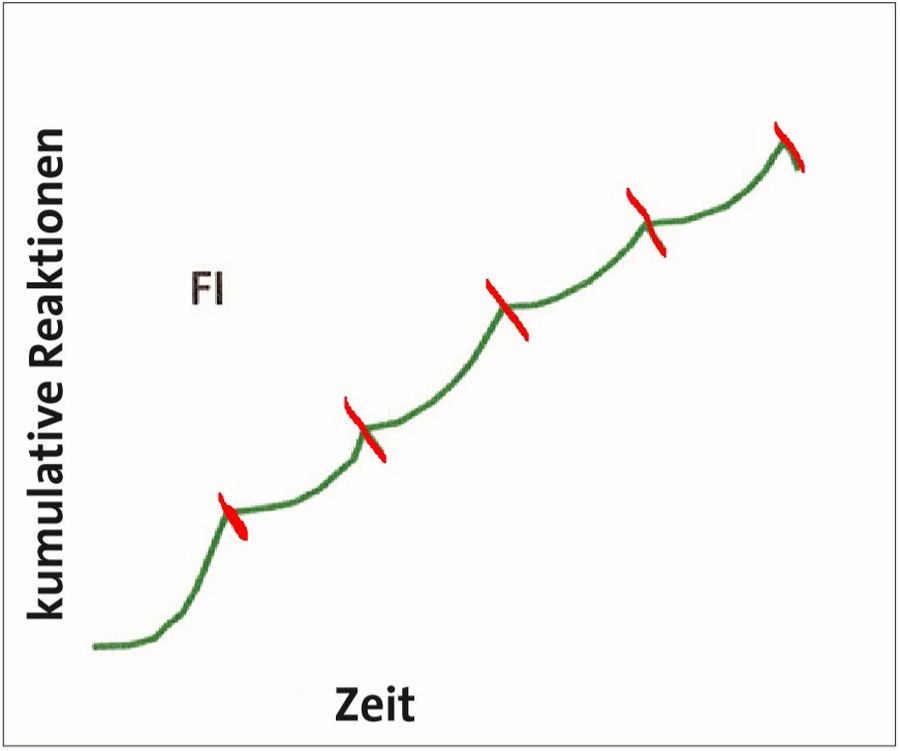
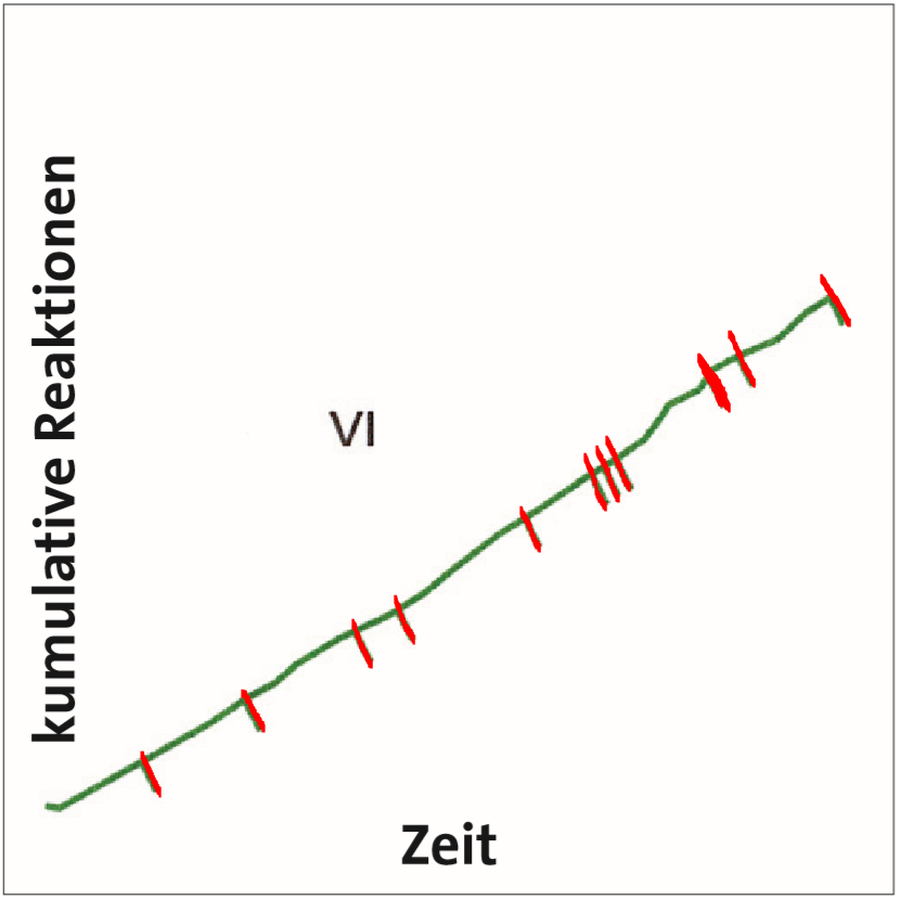
Die Beobachtungen in der Löschungsphase der Experimente zu Intervallplänen ähnelten ebenfalls denen aus dem Versuchen zu Quotenplänen: Die Löschungsresistenz des konditionierten Verhaltens fällt desto höher aus, je länger das Intervall, egal ob fix oder variabel, in der Akquisitionsphase gewählt war.
Welche Schlüsse und Fragen ergaben sich aus den Versuchen?
Aus den Versuchen zu den grundlegenden und einfachen Verstärkerplänen ergeben sich drei Themen, die festgestellt wurden und die jeweils neue Fragen aufwarfen.
Wenn in einem Quotenplan die Anzahl der Reaktionen, also die Anzahl der Picks auf den Schalter, oder in einem Intervallplan die Länge der Intervalle zwischen den Verstärkungen heraufgesetzt wird, sinkt die Extinktionsrate. Durch intermittierende Verstärkungspläne wird also ein Verhalten durch geringere Mengen an Verstärkung löschungsresistenter konditioniert. Dies läuft aber dem Kontingenzprinzip zuwider. Dieses verlangt, wie wir schon gesehen haben, dass das Auftreten der Verstärkung durch die konditionierte Reaktion vorhergesagt werden können muss.
Dass die Akquisitionsrate ebenfalls runtergeht und der Verhaltenserwerb damit auch länger dauert, könnte hier einen ersten Hinweis zur Lösung dieser als Humphreys Paradox bekannten Frage liefern. Um hier mehr Licht ins Dunkel zu bringen, könnte es sich lohnen, schon im nächsten Abschnitt das Experiment von Tolman, das er mit Honzik im Jahr 1930 durchführte, zu beschreiben. Die im übernächsten Abschnitt aufgeführten Erklärungsansätze ändern an den Fakten und der Praxis wenig und sind der Vollständigkeit halber beschrieben.
Auch wurde festgestellt, dass feste Quoten zu Nachverstärkungspausen führen, in denen die gewünschte Reaktion nicht mehr gezeigt wird. Je höher die Quoten, desto länger wurde die Nachverstärkerpause. Die Wissenschaft war nun bestrebt, die Ursachen hierfür zu erforschen.
In den Versuchen zu fixen Intervallplänen konnte etwas ähnliches beobachtet werden: Hier lag die Aktivität nach einer Verstärkung auch niedrig und nahm exponentiell zu, bis sie kurz vor dem Zeitpunkt der nächsten Verstärkung einen Höchstwert erreichte.
Da auch festgestellt wurde, dass weder Nachverstärkungspausen noch die in den Intervallplänen beobachteten Pausen in den variablen varianten der Pläne auftraten und diese sich durch wünschenswert kontinuierliche Reaktionsraten auszeichnen, erscheint es sinnvoll, variable Quoten- und Intervallpläne versuchsmäßig zu vergleichen, um zu sehen, welche Pläne in der Praxis die gewünschten Ergebnisse erbringen und warum das so ist.
Edward Tolman und das Labyrinth für Ratten
Auch der 1886 in Massachusetts geborene Edward Tolman war als Psychologe ebenfalls Anhänger einer Art des Behaviorismus. Im Gegensatz zu Skinner, der nicht messbaren Vorgängen im Inneren eines Lebewesens keine Beachtung schenkte, war Tolman an diesen dennoch interessiert, was den Berkeley-Professor zu einem Vorreiter einer anderen Strömung, nämlich des Kognitivismus, werden ließ. Im Jahr 1930 führte er, unterstützt durch einen Kollegen namens Hoznik das für uns wesentliche Experiment an Ratten in einem Labyrinth durch, bei dem es darum ging, die Wirkung der Verstärkung auf den Verhaltenserwerb oder das Lernen zu ermitteln.
Der Versuchsaufbau und -ablauf
Es wurde ein Labyrinth gebaut, in dem es neben einem immer gleichen Startpunkt 14 Sackgassen gab, von denen eine als Zielstelle diente und an deren Ende eine Futterschale gestellt wurde.
Nun wurde an 17 aufeinanderfolgenden Tagen Laborratten in das Labyrinth gesetzt und gemessen, wie viele Fehler sie pro Durchgang machten, indem sie in eine falsche Sackgasse abbogen. Sie wurden erst aus dem Labyrinth genommen, wenn sie am Ziel angekommen waren.
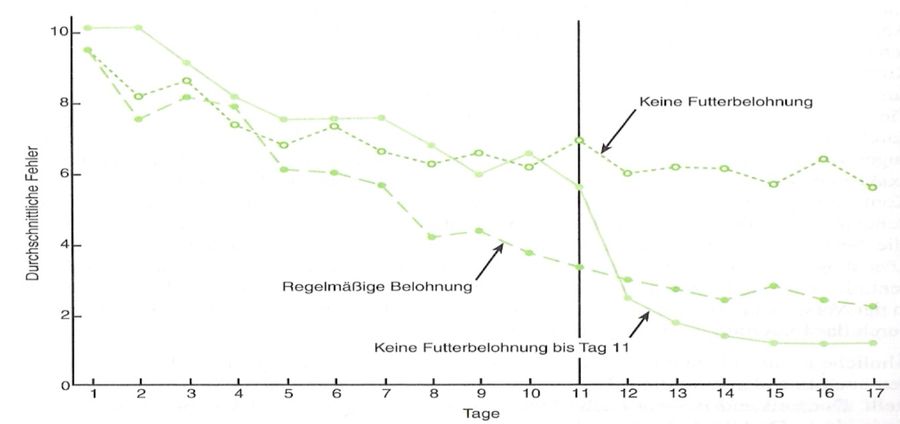
Um die Wirkung der Verstärker zu ermitteln, wurden die Ratten in drei Gruppen aufgeteilt. Gruppe 1 bekam an jedem der 17 Tage Futter in die Schale, während für Gruppe 2 an keinem der Tage die Schale gefüllt war. Die dritte Gruppe fand erst ab dem 11. Tag Futter in der Schale.
Die Ergebnisse des Versuchs
Es zeigte sich für die jeden Tag mit Futter verstärkte Gruppe 1 ein typisches Bild: Die Fehlerquote sank kontinuierlich von knapp 10 Fehlern auf knapp über 2. Ebenso erwartbar war das Ergebnis für die nie verstärkte Gruppe 2, die ihre Fehleranzahl nur minimal von 10 auf ca. 6,5 senken konnte.
Beachtenswert sind aber die Messungen für die Gruppe 3, die ab dem 11. Tag Futter am Zielpunkt vorfand und bis zu diesem Zeitpunkt, wie Gruppe 2, kaum ihre Fehlerquote senkte. Allerdings kam es zu einem abrupten Leistungsanstieg am 12. Tag: Wurden im 11. Durchgang noch durchschnittlich 6 Fehler gemacht, waren es im 12. nur mehr knapp über 2. Ab diesem Durchgang machte diese Gruppe weniger Fehler als die immer verstärkte Gruppe 1.
Die Schlüsse aus dem Versuch: Der Unterschied zw. Lernen und Performance
Tolman und Hoznik sahen also, dass die Ratten, die erst ab einem späteren Zeitpunkt eine Verstärkung erhielten, von einem Durchlauf zum anderen einen Leistungssprung in dem als „orientiere Dich in einem Labyrinth“ zu bezeichnenden Verhalten hinlegten.
Daraus schlossen sie, dass es einen Unterschied zwischen dem Erlernen eines Verhaltens und dem Zeigen dieses Verhaltens geben muss: Ein solcher Leistungssprung wäre nicht möglich gewesen, wenn die betreffenden Ratten nicht in den ersten 11 verstärkungsfreien Durchläufen schon gelernt hätten, sich in dem Labyrinth zu orientieren und somit Kompetenz aufgebaut hätten. Diesen Lernvorgang nannten sie latentes Lernen.
Aber erst die Verstärkung durch Futter ließ die Ratten das Verhalten zeigen oder performen. Insofern haben Verstärker rein motivierende Wirkung, ein Verhalten zu zeigen. Natürlich stellt das Lernen selbst ein Verhalten dar, das über Verstärker motiviert werden kann.
Was bedeutet das für die Akquisitionsraten und damit für die Lerngeschwindigkeit?
Bei der Akquisitionsrate im Rahmen der Konditionierung scheint es also weniger darum zu gehen, dass ein Lebewesen ein bestimmtes Verhalten erlernt oder erwirbt, sondern darum, die Kette aus Hinweisreiz, Verhalten und Verstärker zu erkennen. Es geht um das Erlernen, ob und wann es sich lohnt, ein bestimmtes Verhalten zu zeigen oder zu performen und weniger darum, das bestimmte Verhalten zu erlernen: Auf einen Knopf picken, kann jede Taube und jeder Hund kann auch generell eine sitzende Position einnehmen. Insofern haben Verstärker rein motivierende Wirkung, ein Verhalten zu zeigen. Natürlich stellt das Lernen selbst ein Verhalten dar, das über Verstärker motiviert werden kann.
Drei Theorien zur Extinktionsrate – selbes Ergebnis
Diese Idee scheint auch in der von Mowrer und Jones 1945 formulierten Diskriminationshypothese durch. Dieser zur Folge tritt eine Verhaltensänderung erst dann, wenn eine Verstärkungskontingenzänderung erkannt wird. Die Änderung in der Verstärkungskontingenz dient als Hinweis- oder Diskriminationsreiz für die Verhaltensänderung. Dies bezieht sich sowohl auf die Akquisition als auch auf die Löschung: Je seltener eine Verstärkung erfolgt, desto länger dauert es, bis ein Zusammenhang zwischen einem bestimmten Verhalten und der Verstärkung erkannt und das Verhalten als lohnenswert eingestuft wird, wodurch die Akquisitionsrate gegenüber Verstärkerplänen mit häufigerer Verstärkung abnimmt. Allerdings dauert es auch umso länger, bis eine erneute Änderung der Verstärkungskontingenzen, im Falle der Löschung ist das der Wegfall der Verstärkung, erkannt wird. Durch die verzögerte Wahrnehmung dieser Änderung, die als Hinweisreiz für eine erneute Verhaltensänderung, nämlich der Löschung, dient, wird das Verhalten auch ohne Verstärker länger gezeigt, womit es löschungsresistenter ist.
Eine neuere Theorie aus dem Jahr 1966, von Capaldi entwickelt, stellt die Generalisierung in den Fokus. Unter Generalisierung verstehen die Verhaltensforscher die Fähigkeit von Organismen, auf unterschiedliche Reize gleich zu reagieren. Als einfaches Beispiel könnte dienen, dass ein Hund auf das Kommando „Platz“ und „Ablegen“ hin dasselbe Verhalten zeigt und sich hinlegt. Eine solche Generalisierung muss aber ebenfalls trainiert werden, was im Fall der Löschung nicht geschieht: Von der Immer-Verstärkung in der Akquisitionsphase ausgehend tritt eine abrupte Änderung der als Verstärkung verabreichten Reizen ein: es gibt ab jetzt keinen Reiz mehr. Eine solche abrupte Änderung entfällt bei den Intervall- und Quotenplänen: Schon in der, durch die seltener verabreichten Verstärkungen länger dauernden, Akquisitionsphase wurde die entsprechende Generalisierung trainiert.
Last but not least ist die kognitive Erklärung zu nennen. Sie ist schon deshalb aufzuführen, weil wir uns schon auf das Experiment von Tolman bezogen haben und er den Begründer des Kognitivismus ist. In dieser Theorie wird die Erwartungshaltung ins Zentrum gerückt: Die durch die Immerverstärkung genährte Erwartung, einen Verstärker nach jeder Reaktion zu erhalten, führt schnell zu Enttäuschung und Einstellung der Reaktion, wenn die Verstärkung ausbleibt. Die Erwartung bei einem Quoten- oder Intervallplan ist hingegen eine viel niedrigere, sodass die Enttäuschung auch viel niedriger ist, wenn für einige Reaktionen keine Verstärkung erfolgt.
Theorien und Versuche zur Nachverstärkungspause
Die Nachverstärkungspause ist ein Problem, dass es sich zu untersuchen lohnt. Schließlich ist gewollt, dass ein gewünschtes Verhalten oder eine Reaktion vorhersehbar erfolgt und nicht, dass es vorhersehbar NICHT erfolgt. Vorgeschlagen wurden die Sättigungs-, die Ermüdungs- und die Verstärkerdistanzhypothese. Die ersten beiden Hypothesen sind selbsterklärend, die letzte geht davon aus, dass die Pause davon abhängt, wie viele Wiederholungen gezeigt werden müssen, bis die nächste Verstärkung kommen wird: Je höher die Quote und damit je mehr Wiederholungen gefordert sind, desto länger die Pause.
Wie oben beschrieben, nahmen die Nachverstärkerpausen zu, je höher die Quoten waren. Da mit steigender Quote die Menge der Verstärkung abnahm, kann davon ausgegangen werden, dass die Sättigungshypothese nicht die richtige Erklärung ist: Mehr Futter als Verstärkung und damit eine schnellere Sättigung gibt es bei niedriger Quote. Gerade dann aber fällt die Nachverstärkerpause kürzer statt länger aus.
Um zu überprüfen, ob nun eher die Ermüdung oder die Distanz, gemessen in Wiederholungen der entsprechenden Reaktion, für die Nachverstärkerpause ausschlaggebend war, wurde in den 1960er Jahren experimentiert.
Versuchsablauf zur Ermüdungs- und zur Verstärker-Distanz-Hypothese
Auch wenn die genaue Versuchsanordnung nicht recherchierbar ist, kann wohl von folgendem in einer Skinner-Box ausgegangen werden: Es gab eine Schaltfläche und einen Spender. Anders als bisher war es allerdings möglich, die Schaltfläche rot oder blau erleuchten zulassen und an die Farben unterschiedliche Quotenpläne zu knüpfen: Leuchtet der Schalter rot, gilt ein FR10 mit 10 Wiederholungen bis zur Verstärkung. Leuchtet er blau, gilt ein FR100.
Nun wurden die Versuchstiere, vermutlich Tauben, die sehr schnell picken können und für die 10 Wiederholungen eine Sache von Sekunden sind, in die Boxen gesetzt. Nach der Akquisitionsphase, in der die Tiere auch die Farben als Hinweisreiz für den jeweils geltenden Quotenplan verknüpfen mussten, wurden nun die Nachverstärkerpausen der Tiere für die beiden unterschiedlichen Quotenpläne gemessen.
Das Ergebnis des Versuchs
Das Ergebnis des Versuchs war, dass die Tiere dann eine längere Nachverstärkerpause machten, wenn der Schalter blau leuchtete und damit signalisierte, dass 100 Wiederholungen bis zur nächsten Verstärkung gemacht werden mussten. Kürzer viel sie entsprechend aus, wenn die Taste rot leuchtete und damit anzeigten, dass nach nur 10 Picks eine Verstärkung zu erwarten ist. In der Abbildung ist gut zu erkennen, dass zunächst ein FR100 verlangt und von den Tieren mit einer Pause begonnen wird. Nach erfolgter Verstärkung wird signalisiert, dass bis zur nächsten Verstärkung nur 10 Wiederholungen nötig sind. Dennoch ist die Nachverstärkerpause hier kürzer, als die allererste. Dieses Muster ist über den gesamten Verlauf erkennbar und lässt
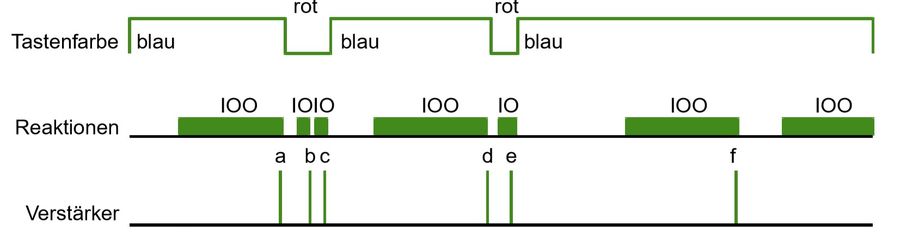
klar die Deutung zu, dass die Nachverstärkerpause davon abhängt, wie groß die Distanz, gemessen in Wiederholungen, zur nächsten Verstärkung ist und nicht von einer zu Beginn des Versuchs noch nicht wahrscheinlichen Müdigkeit abhängt.
Insofern ist „Nachverstärkerpause“ ein verwirrender Begriff, da er wohl mehr mit dem auch uns Menschen bekannten Überwinden des inneren Schweinehundes zu tun haben scheint, als damit, dass gerade ein Verhalten verstärkt wurde.
Theorie zur Entstehung des FI-Bogens
Bei einem Verstärkungsplan, der sich an festen Intervallen ausrichtet, wird nur die erste Reaktion nach einer bestimmten Zeit verstärkt. Im Umkehrschluss werden all jene Reaktionen, die vor dieser Zeit erfolgen, nicht verstärkt. Um ein möglichst effizientes Verhältnis zwischen Reaktionen (also auch Aufwand) und Verstärkung (also Ergebnis) zu erzielen, das dann erreicht wäre, wenn nur eine Reaktion unmittelbar nach verstreichen des Zeitintervalls gezeigt und verstärkt würde, erscheint es logisch, dass unmittelbar nach einer verstärkten Reaktion die Reaktionsrate heruntergeht.
Im Gegensatz dazu steht der variable Intervallplan, bei dem die Reaktionsrate nach einer verstärkten Reaktion nicht heruntergeht, weil hin und wieder das Intervall so kurz ist, dass die nächste Reaktion nach einer Verstärkung wieder verstärkt wird.
Experimenteller Vergleich der beiden variablen Verstärkungspläne
Nachdem die Wissenschaft sich und in Folge dessen auch wir uns nun mit sehr theoretischen Themen befasst haben, die uns aber nur als Hintergrundwissen ohne weitere praktische Bedeutung im Umgang mit unseren Hunden dienen, wenden wir uns nun der Frage zu, welche der beiden variablen intermittierenden Verstärkerpläne wohl der effizientere ist.
Der Versuchsaufbau und -ablauf
Um variable Quoten- (VR-Plan) mit variablen Intervallplänen (VI-Plan) zu vergleichen, verwendete man als Versuchstiere Tauben, die einige Tausendmal in der Stunde auf einen Schalter picken können. Die Tiere wurden jeweils in Gruppen aufgeteilt und entweder in einer Skinner-Box nach einem VR- oder VI-Plan konditioniert wurden. In mehreren Versuchsreihen wurden viele verschiedene Intervalle von sehr kurz zu sehr lang sowie kleine und große Quoten getestet.
Um nun Intervallpläne mit Quotenplänen vergleichen zu können, musste bei allen Versuchen eine Uhr mitlaufe. Ziel war es, die Anzahl der Reaktionen pro Minute und die Anzahl der Verstärker pro Stunde zu messen. Auf diese Weise konnte nach Quotenplänen konditioniert werden, diese aber bei der Datenauswertung wie Intervallpläne, die ja immer zeitabhängig sind, dargestellt und somit vergleichbar gemacht werden.
Die Ergebnisse des Versuchs
Wie aus der unten stehenden Abbildung hervorgeht, zeigten die Tauben bei den variablen Quotenplänen mehr Reaktionen, drückten also beispielsweise öfter die Taste, bei selber Menge Futter und damit derselben Menge an Verstärkern pro Stunde, als bei den variablen Intervallplänen.
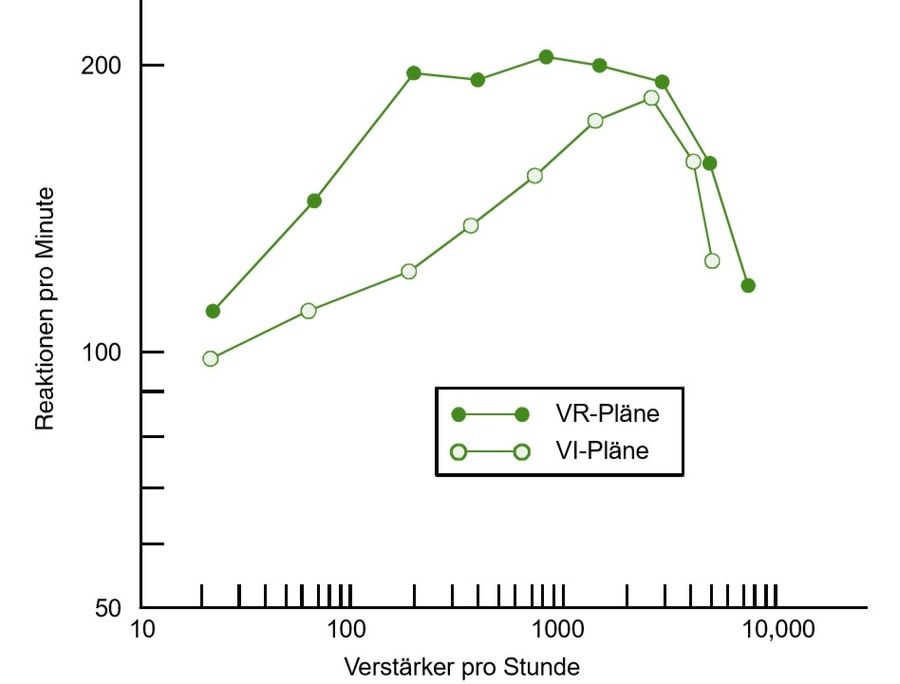
Die Schlüsse und Fragen aus dem Versuch
Praktisch relevant ist die Erkenntnis, dass innerhalb der löschungsresistenteren variablen Verstärkungsplänen also die Quotenpläne diejenigen sind, die mehr Reaktionen, also Wiederholungen des konditionierten oder antrainierten Verhaltens bringen und die somit effizienter erscheinen: Schließlich wollen wir, dass unsere Hunde häufig bis immer tun, was wir trainiert oder konditioniert haben.
Eine gewisse praktische Relevanz in der Hundeerziehung hat auch, dass bis zu einer gewissen Menge gilt: Je kleiner die Quote (oder das Intervall), desto mehr Reaktionen werden gezeigt. Ab einer gewissen Menge werden wieder weniger Reaktionen gezeigt. Das könnte daran liegen, dass das Bedürfnis, das mit dem Verstärker gedeckt werden soll, übererfüllt ist: Bei 10.000 Futtergaben pro Stunde sind auch die hungrigsten Tauben irgendwann satt und empfinden die Futtergabe nicht mehr als positiven Reiz.
Wissenschaftlich wurden zwei unterschiedliche Theorien entwickelt, die das Ergebnis begründen, die aber im Grunde keine praktische Auswirkung haben.
Der von Skinner begründete molekulare Ansatz geht davon aus, dass nur kurze Vorgänge und Zusammenhänge, die sich in Zeiträumen von maximal einer Minute ereignen, erkannt werden können. Aus dieser Annahme entwickelte er die „Interresponse-Time-Reinforcement-Theory“, was in etwa so viel heißt wie „Zwischenreaktionszeit-Verstärkungs-Theorie“. Dieser zufolge werden bei variablen Quotenpläne kürzere Pausen verstärkt und bei variablen Intervallplänen längere Pausen verstärkt, da die Wahrscheinlichkeit, dass die nächste Reaktion mit einer Verstärkung belohnt wird, nach einer längeren Pause steigt.
Der molare Ansatz geht davon aus, dass über die Zeit hinweg auch größere und Zusammenhänge erkannt werden, die über eine Minute hinausreichen. Hierzu entstand die „Reinforcer-Correlation-Theory“, die besagt, dass kurzfristige Änderungen im Verhältnis der Anzahl an Reaktionen und Verstärkern nicht relevant sind, aber langfristig erkannt wird, dass mehr Reaktionen in einem variablen Intervallplan nicht mehr Verstärkung ergibt, während in einem variablen Quotenplan mehr Reaktionen auch mehr Verstärkung bedeutet.
Die perfekte Synthese: gemischte Verstärkungspläne
Wenn wir uns nun überlegen, welche Kriterien für die Bewertung eines Verstärkungs- oder Trainingsplans relevant sind, kommen wir mindestens auf die folgenden vier:
a) Hohe Akquisitionsrate/Lerngeschwindigkeit
b) Hohe Löschungsresistenz
c) Keine Nachverstärkerpause
d) Hohe Reaktionsrate im Verhältnis zu den Verstärkermengen.
Leider müssen wir nun feststellen, dass die Immerverstärkung zwar eine hohe Lerngeschwindigkeit bringt, aber eine extrem niedrige Löschungsresistenz, wenn mal nicht verstärkt wird. Das würde uns dazu verdonnern, immer mit Leckerchen in der Tasche unterwegs zu sein und führte uns in Teufels Küche, wenn wir die Leckerchen mal daheim vergessen.
Um dem zu entgehen, würden wir am besten nach einem intermittierenden Plan, also entweder einem Quoten- oder Intervallplan konditionieren. Um zu vermeiden, dass nach einer gut ausgeführten Aktion, die wir verstärken, unsere Hunde in der Nachverstärkerpause erstmal machen, was sie wollen, sollte der Plan variabel gestaltet sein, damit für die Tiere nicht vorhersehbar ist, wann die nächst Verstärkung kommt.
Auch haben wir gesehen, dass wir einen variablen Quotenplan einem variablen Intervallplan vorziehen sollten und vor allem, und das ist das größte Problem: Je größer die Quote eines Plans, desto löschungsresistenter ist das aufgebaute Verhalten. Leider dauert aber auch die Phase, in der das Verhalten konditioniert wird, sehr viel länger.
Bei der Vielzahl an Verhaltensweisen, die wir unserem besten Freund vermitteln wollen, würde das bedeuten, dass wir ihn erst im höchsten Alter grundlegend erzogen hätten.
Die Lösung liegt nun in einem gemischten Verstärkerplan: Zum grundlegenden Verhaltensaufbau, den wir schnell erreichen möchten, verstärken wir immer. Ist das Verhalten grundsätzlich konditioniert, stellen wir schrittweise und langsam auf immer höhere variable Quoten um. Hierbei kommt es darauf an, die Verstärkung immer früh genug zu geben, damit die Löschungsphase nicht eintritt. Sollte diese doch eintreten, muss die Spontanerholung für die Verstärkung genutzt werden.
Bei all dem hat aber Skinner schon früh ein weiteres Problem erkannt: Wenn die Basisrate eines noch nicht konditionierten Verhaltens sehr niedrig ist, kann man unter Umständen tagelang warten, bis es zufällig gezeigt wird und verstärkt werden kann. Schon in den 1930er und 40er Jahren entwickelte er hierfür eine Lösung, der wir uns nun zuwenden werden.
Skinner & die Beschleunigung der Konditionierung - Shaping & Chaining
Schon in seinen ersten Versuchen zur positiven Verstärkung stellte Skinner fest, dass Tauben zwar eine hohe Basisrate für das Verhalten Picken aufweisen, weil sie häufig den Schnabel einsetzten, um Dinge zu untersuchen, aber dennoch häufig viel Zeit verging, bis eine Taube nicht irgendwohin pickte, sondern zufällig auf den Schalter pickte und verstärkt werden konnte. Aus dieser Beobachtung ergaben sich für Skinner neue Forschungsziele.
Skinners Forschungsziel: schnellere Konditionierung einfacher Verhaltensweisen
Zunächst stellte sich Skinner die Frage, ob sich ein Weg findet, dass die Tauben schneller beginnen, nicht mehr wahllos zu Picken, sondern auf den Schalter zu picken.
Andererseits war er sich wohl bewusst, welche Faktoren einen Einfluss auf die Basisrate eines Verhaltens haben. Zum einen ist wohl die Baseline eines Verhaltens dann höher, wenn es ein instinktives, natürliches Verhalten ist: Jeder Hund stellt, setzt oder legt sich aus freien Stücken von Zeit zu Zeit hin, während er wohl selten oder nie aus freien Stücken „Männchen“ macht. Daher ist die Basisrate von „Steh“, „Sitz“ und „Platz“ weit höher als die von „Männchen machen“. Ist die Basisrate eines Verhalten 0, wird es also gar nicht gezeigt. Heute spricht man dann davon, dass es nicht im (Verhaltens)Repertoire enthalten ist.
Dies entspricht Skinners Problem, dass er mit den Tauben hatte: Das Picken auf den Schalter hatte zwar eine Baseline, aber eine sehr niedrige und ist noch nicht im Repertoire. Er überlegte sich, ob nicht das Verhalten formbar, auf Englisch „shapeable“ sei, woraus er die Methode des Shapings entwickelte.
Der Versuchsaufbau beim Shaping
Skinner verwendete hier zunächst wieder eine seiner Boxen, die nun so modifiziert wurde, dass Skinner als Versuchsleiter über eine Fernbedienung eine verhaltensverstärkende Futtergabe auslösen konnte. Nun wurde jede noch so kleine Hinwendung in Richtung der zu pickenden Taste verstärkt: Drehte die Taube den Kopf leicht in Richtung der Wand, an der der Knopf sich befand, wurde das Verhalten verstärkt. Auf diese Weise zeigte die Taube das Hinwenden des Kopfes in die richtige Richtung öfter. Basierend darauf werden alle weiteren Annäherungen ebenfalls verstärkt: Sobald nun der Kopf noch weiter in die richtige Richtung ging, oder gar der Körper mitgedreht wird oder ein Schritt auf die Wand zu gemacht wird. Wenn die Taube nun an der Wand mit der Taste angekommen ist, wird, entsprechend dem bisherigen Vorgehen, jede weitere Annäherung verstärkt, bis die Taste gedrückt ist und dadurch der bekannte Mechanismus der Skinner Box die Verstärkung auslöst.
Im weiteren Verlauf seiner Forschung formte er so auch andere Verhaltensweisen bei seinen Tauben. Beispielsweise nutzte er Shaping, um sich Tauben um ihre eigene Achse drehen zu lassen, indem er eben jede auch noch so kleine Bewegung in die gewünschte Richtung verstärkte.
Ergebnisse und sich ergebende Fragen aus den Shaping-Versuchen
Skinner konnte somit feststellen, dass durch Shaping deutlich weniger Zeit nötig war, um Lebewesen auf einfachere, wenn auch unnatürliche Verhaltensweisen zu konditionieren.
Es war den Wissenschaftlern aber auch klar, dass die Komplexität eines Verhaltens ebenfalls eine Einflussgröße ist. Nehmen wir nochmal unser Hunde-Beispiel: Selbst, wenn „Männchen“ mit selber Häufigkeit wie „Steh“, „Sitz“ oder „Platz“ gezeigt würde und alle Verhaltensweisen im Repertoire wären, würde es sehr lange dauern, bis ein Hund eine spezielle Verhaltensabfolge aus allen Einzelverhalten zeigen würde. Wenn wir nur verstärken möchten, wenn die Abfolge exakt „Platz“ – „Sitz“ – „Steh“ – „Männchen“ – „Steh“ – „Sitz“ – „Platz“ ist, können wir wohl ewig warten. Um solche Verhaltensketten, wie sie korrektes Apportieren darstellen, zu konditionieren, wurde als Alternative zum Shaping das Verketten von Verhaltensweisen, das Chaining experimentell erforscht.
Theorie zum Chaining
Nicht recherchierbaren wissenschaftlichen Ursprungs ist das Chaining, das aber ebenfalls mit Skinner in Verbindung gebracht wird und über das komplexere Ketten aus einfacheren Einzelverhalten konditioniert werden können, an deren Ende ein primärer Verstärker wie Futter, gewissermaßen als Endziel des zu konditionierenden Lebenwesens, zur Verfügung gestellt wird.
Chaining gibt es in drei verschiedenen Varianten, von denen eine, nämlich das Total Task Chaining, nur in der menschlichen Verhaltenstherapie, nicht aber in der Konditionierung von Tieren eine Rolle spielt.
Die beiden für das Tiertraining interessanten Chaining-Arten unterscheiden sich nach der Art des Aufbaus der Verhaltenskette. Wird die Verhaltenskette vom ersten Schritt aus aufgebaut, spricht man vom Vorwärtsverkettung oder Forward Chaining. Dieses unterscheidet sich vom Shaping nur durch die Komplexität des zu konditionierenden Verhaltens. Entsprechend unscharf sind die Grenzen zwischen den beiden Techniken.
Daher wird in der Verhaltenspsychologie heutzutage unter Chaining primär das Backward Chaining oder die Rückwärtsverkettung verstanden, bei dem zuerst das letzte Glied der Verhaltenskette konditioniert und dann Schritt für Schritt rückwärts bis zum ersten notwendigen Einzelverhalten vorgegangen wird.
In beiden Fällen muss sich der Trainer vor Beginn des Chainings über die Aufteilung der Verhaltenskette in einzelne Glieder, die ggf. einzeln durch Shaping oder andere Techniken zu konditionieren sind, bewusst werden. Diesen Vorgang nennt man Task Analysis oder Aufgabenanalyse.
Die beispielhafte Verhaltenskette
Im Versuch könnte eine dreigliedrige Verhaltenskette folgendermaßen definiert worden sein:
Eine Ratte befindet sich auf dem Boden der Box, soll eine Treppe hochlaufen, oben einen Schalter bedienen, der den Weg zu einer Rutsche freigibt, über die sie wieder in das Erdgeschoss hinabrutschen soll, wobei die Benutzung der Rutsche über eine Lichtschranke den Futtermechanismus der Skinner-Box auslöst.
Backward Chaining
Bei der Rückwärtsverkettung wird also mit dem letzten Verhaltensglied, in unserem Fall also der Benutzung der Rutsche, begonnen. Dazu könnte man die Ratte im Obergeschoss platzieren. Außer der Rutsche führt kein Weg nach unten, sodass die Ratte früher oder später die Rutsche benutzen wird, was die Lichtschranke unterbrechen und die Verstärkung über Futter bewirken würde. Das entspräche soweit der üblichen positiven Verstärkung im Rahmen der operanten Konditionierung. Nun müsste ein Helfer die Ratte zur Wiederholung wieder ins Obergeschoss setzen, damit das Verhalten gefestigt werden kann, was dazu führt, dass der Anblick der verfügbaren Rutsche zum diskriminativen Hinweisreiz (Sd) wird, diese zu verwenden, um unten als verstärkenden Reiz (Sv) die Nähe und Verfügbarkeit des Futters wahrzunehmen.
Ist dies geschehen, wird aber der Zugang zur Rutsche durch eine Art Tür versperrt. Diese Tür kann geöffnet werden, wenn die Ratte den schon aus anderen Experimenten bekannten Hebel nach unten drückt: Dadurch wird dann nicht der Futterspender aktiviert, sondern die Tür zur Rutsche geöffnet. Der Anblick der frei zugänglichen Rutsche wird somit zum konditionierten Verstärkerreiz für das Drücken des Hebels: Erst die offene Tür ermöglicht die Nutzung der Rutsche und damit den Zugang zum Primärverstärker „Futter“. Nun erfüllt der Anblick der freien Rutsche also zwei Funktionen: Er ist verstärkender Reiz für das Hebeldrücken und Hinweisreiz für die Nutzung der Rutsche.
Ist die Verhaltenskette soweit gefestigt, wird die Ratte ins Erdgeschoss gesetzt, wo ihr der Anblick einer Treppe als Aufgang in Obergeschoss geboten wird (die Rutsche sei zu glatt). Nutzt die Ratte die Treppe nach oben, erblickt sie dort das schon bekannte Szenario aus Hebel und verschlossener Rutsche. Dieser Anblick ist hat nun wiederum gleichermaßen verstärkende Wirkung für das Erklimmen der Treppe, als auch immer noch den schon bekannten auslösenden Effekt als Hinweisreiz für die Betätigung des Hebels. Bei ausreichend häufiger Wiederholung wird hierbei der Anblick der Treppe zum auslösenden Hinweisreiz für die gesamte Kette.
Im folgenden Bild wird der Prozess schematisch dargestellt.
Forward Chaining
Bei der Vorwärtsverkettung wird mit dem ersten Glied in der Verhaltenskette begonnen, die nach korrekter Reaktion mit einem primären Reiz wie Futter verstärkt wird. Wird das nächste Kettenglied angehangen, wird dieser Verstärker erst zugänglich gemacht, wenn beide Reaktionen korrekt ausgeführt werden.
Um bei unserem Beispiel zu bleiben, würde also die Ratte zunächst ins Erdgeschoss der Skinner-Box gesetzt und mit Futter verstärkt, wenn sie die Treppe nach oben benutzt. Macht sie das zuverlässig, würde eine Verstärkung nur noch erfolgen, wenn sie den Schalter betätigt und zuletzt würde nur noch bestätigt, wenn abschließend auch die Rutsche benutzt worden wäre. Natürlich könnte die Skinner-Box auch hier einige Male angepasst werden, beispielsweise könnte die Rutsche erst später eingebaut werden, um zu verhindern, dass die Ratte über die Rutsche nach oben läuft. Auch könnte anfänglich auf den Schalter verzichtet werden, um zu verhindern, dass er zufällig bedient wird, ohne dass eine Verstärkung erfolgt.
Die folgende Abbildung zeigt das Prinzip, wieder mit den schon bekannten Abkürzungen.
Welche Chaining-Art sollte verwendet werden?
In der Literatur zur Verhaltenstherapie für Kinder ist zu lesen, dass Backward-Chaining sich für Kinder eignet, die den Sinn im Endergebnis der Verhaltenskette nicht erkennen und deren Lernmotivation gering ist.
Nun kann man bei unseren Tieren davon ausgehen, dass sich ihnen der Sinn mancher von uns gewünschten Verhaltensweisen nicht erschließt und dass sie lieber spielen, als unseren Anweisungen zu folgen. Aus diesem Grund könnte die Rückwärtsverkettung sinnvoller als die Vorwärtsverkettung erscheinen.
In dem von mir oben gewählten Beispiel können trotz aller Umbaumaßnahmen in der Skinner-Box ebenfalls Schwierigkeiten bei der Vorwärtsverkettung auftreten: Wenn nämlich die Ratte für viele Reaktionen immer oben auf der Plattform verstärkt wird, und ist es ein recht harter Bruch, wenn die Verstärkung dort nicht mehr gereicht wird, sondern unten.
Für die Vorwärtsverkettung spricht aber ganz klar, dass sie dem Shaping sehr ähnlich ist. Was das für das Hundetraining konkret bedeutet, wird in dem Abschnitt, der sich konkreter mit der Hundeerziehung befasst, noch näher beleuchtet.
Kritik an Skinners Verstärker Definition & aktuelle Theorien
Nachdem Edward Tolman oben im Text gezeigt hat, dass Verstärker nicht erforderlich sind, um Verhalten zu erwerben oder zu erlernen, sondern als Motivatoren dienen, um Verhalten zu zeigen oder zu performen, wenden wir uns nun der Frage zu, was denn als Verstärker dienen kann und behalten im Hinterkopf, dass die folgenden Forscher sich tatsächlich mehr mit Rolle von Verstärkern als Performance-Motivatoren befassten, als ihre Rolle beim Verhaltenserwerb, also beim Lernen zu erforschen.
Die Schwächen Skinners
Wie wir gesehen haben, als wir uns oben mit dem Kontingenzschema beschäftigt haben, ergibt sich aus Skinners Theorie nicht von vorne herein, was ein Verstärker oder eine Strafe ist. Vielmehr kann das nur anhand der Auswirkung erkannt werden: Folgt ein Reiz regelmäßig auf ein Verhalten und wird dieses immer häufiger gezeigt, handelt es sich um eine positive Verstärkung. Sinkt die Häufigkeit des Verhaltens, handelt es sich um einen aversiven Reiz, um eine positive Strafe. Ein solcher Zirkelschluss nutzt uns im praktischen Alltag nun wenig, da wir VOR der Verabreichung des fraglichen Reizes wissen müssen, ob es sich um eine appetitive, angenehme Belohnung handeln wird, die das Verhalten festigt oder um eine aversive, unangenehme Strafe handeln wird, die das Auftreten des Verhaltens senkt. Außerdem war die durch den beschriebenen Zirkelschluss begründete Unmöglichkeit, vor Beginn der Konditionierung sicher zu wissen, was ein angenehmer Reiz und was ein unangenehmer Reiz ist für die Wissenschaft unbefriedigend, was zu den hier beschriebenen Theorien und modernen Ansätzen führte.
Skinner selbst griff auf Futter als Verstärkung zurück, von dem unterstellt werden kann, dass es unter den meisten Umständen als angenehm empfunden wird. Stellen wir uns nun aber vor, dass wir nach einem sehr ausgiebigen Mittagessen satt sind oder uns gar derart überfressen haben, dass uns ein bisschen übel wird. In der Situation würden wir es wohl kaum als angenehm empfinden, wenn uns jemand ein Schnitzel vorsetzen würde.
Skinner stellte sicher, dass die Gabe von Futter als angenehm empfunden wurde, indem er seine Versuchstiere vor den Versuchen auf Diät setzte, sodass sie nur noch 80 % ihres normalen Gewichts auf die Waage brachten, was ein klar messbarer Faktor ist.
Nun liegt jedoch der Schluss nahe, dass die Tiere Hunger verspürten, der ebenfalls einen unangenehmen Reiz darstellt. Wird ein solcher, unangenehmer Reiz nach einem bestimmten Verhalten entfernt, spricht Skinner in seinem Kontingenzschema jedoch von negativer Verstärkung, während die Gabe von Futter doch ein angenehmer Reiz ist, was der positiven Bestärkung entspricht. Wie lassen sich vor diesem Hintergrund nun positive von negativer Verstärkung unterscheiden?
Dieses Problem löst Skinner dadurch, dass er die inneren Vorgänge, also Empfindungen wie Hunger oder, bei Menschen, Gedanken nicht beachtete. Er begründete das damit, dass diese nicht messbar seien und verbannte sie in die von ihm sogenannte Black Box. Somit sind Reize also definiert als äußere, beobachtbare und messbare Ereignisse wie die Gabe und Verfügbarkeit von Futter, während Hunger oder Übersättigung nicht zu diesen Reizen gehören. Somit handelt es sich bei dem hier genannten Beispiel dann klar um positive Verstärkung, da der messbare äußere Reiz eben nicht die Beseitigung des unangenehmen Hungers, sondern die angenehme Gabe von Futter ist.
Diese Sichtweise ist zwar zur Beschreibung Skinners Theorie notwendig, aber im Grunde auch sehr unbefriedigend: Für die praktische Anwendung ist, nicht zuletzt aus Liebe zum Tier und tierschutzrechtlichen Gesichtspunkten, die Verbannung von Empfindungen wie Hunger in eine uninteressante Black Box ein kritischer Punkt, dem wir uns jetzt zuwenden werden, um im zweiten Teil der Serie Lösungen für die Hundererziehung vorschlagen zu können. Wichtig ist im praktischen Leben nämlich auch, dass die Aussicht auf Futter nicht immer zur selben Reaktion führt. Auch dieser Umstand führte zu weiterer Forschung.
Die Theorien des Clark Leonhard Hull
Der 1884 in den USA geborene Psychologe Clark Leonhard Hull forschte unter anderem, wie auch Skinner, zu den behavoristischen Lerntheorien, wollte sich aber nicht damit abfinden, dass innere Vorgänge nach Skinners Lehre unbeachtet in einer Black Box abgelegt und nicht weiter beachtet wurden. Da die inneren Vorgänge nicht messbar sind, stellt er Hypothesen über sie, ihren Einfluss auf Verhalten und somit ihre Wirkweise auf. Die Hypothesen drückte er in mathematische Gleichungen aus, deren Korrektheit er und weitere Verhaltensforscher dann im Tierversuch zu überprüfen versuchten.
Da er sich mit inneren Vorgängen beschäftigte und somit versuchte, Farbe in Skinners Schwarze Box zu bringen, ging er über die reine Lehre Skinners hinaus. Wegen dieses Unterschieds gehört Hull zu den Neo-Behavoristen. Aber auch er ging bis zu seinem oben beschriebenen Experiment mit den Ratten im Labyrinth davon aus, dass Verstärkung eine Grundvoraussetzung für das Lernen oder den Erwerb neuer Verhaltensweisen ist. Daher betrachten wir seine Arbeit nicht mehr vor diesem, sondern nur noch vor dem Hintergrund, was Verstärker sind und nicht, wozu genau sie benötigt werden.
Hulls Hypothese zu biologischen Bedürfnissen, Trieb und Triebreduktion als Verstärkung
Stellt man sich aber die Frage, in welcher Situation die Gabe von Futter als angenehm empfunden wird, kann nun davon ausgegangen werden, dass Skinners auf 80 % des Körpergewichts reduzierte Tiere Hunger verspürten, den sie stillen wollten. Das sah auch Hull, Anfang der 1940er Jahre ähnlich: Allgemein ausgedrückt hatten die Tiere also ein Bedürfnis, das sie reduzieren oder decken wollten. Im Fall von Skinners Versuchstieren war es eben Hunger, denkbar wären aber auch andere Bedürfnisse wie Durst, Müdigkeit, Langeweile etc.
Solche Bedürfnisse bilden gemeinsam ein Abbild des bereits 1865 von dem französischen Arzt und Psychologe Claude Bernard proklamierten „Inneren Milieus“, das in einem ausgeglichenen Zustand gehalten werden soll. Ausgeglichen bedeutet, dass für eine Reihe von Faktoren, wie eben dem Wasser- oder dem Nährstoffgehalt in einem Lebewesen, Sollwerte zugeordnet sind. Aus den Abweichungen von diesen Sollwerten ergeben sich die Bedürfnisse.
Aus der Summe der unterschiedlichen Bedürfnisse ergibt sich die Triebstärke (engl. Drive), deren Reduktion eine Verstärkung darstellt. Hull ging davon aus, dass die Triebstärke aus der Summe der Bedürfnisse entsteht, wobei die einzelnen Bedürfnisse (z. B. Hunger gegen Durst) untereinander austauschbar sind.
Da auch er, wie Skinner, möglichst messbare Größen, die er in eine Formel einfügen kann, benötigte, führte er die Deprivationsdauer ein: Es handelt sich hierbei um die Zeitspanne, in der ein Bedürfnis nicht befriedigt, indem beispielsweise Futter oder Wasser vorenthalten wird. Die Deprivationsdauer beschreibt damit die Triebstärke.
Der als Deprivationsdauer gemessene Trieb motiviert also Verhalten und bestimmt, in welchem Maß es gezeigt wird. Da aber die dem Trieb zu Grunde liegenden Bedürfnisse auswirkungslos ausgetauscht werden können, bestimmt seiner Hypothese nach der Trieb nicht die Art des Verhaltens.
Die Art des Verhaltens wird von den Gewohnheiten (engl. Habit) bestimmt. Diese wiederum ergeben sich aus den Reiz-Reaktions-Kopplungen und den daraus resultierenden Verstärkungen oder Belohnungen und Strafen, entsprechend Thorndikes Gesetz der Wirkung, das ebenfalls in Skinners Konditionierung einfließt.
In seiner Formel multipliziert Hull den Trieb, also die Deprivationsdauer, mit der Gewohnheit, ausgedrückt in der Summe der bisherigen Verstärkungen, um die Verhaltensstärke zu erhalten. Daraus ergibt sich, dass kein Verhalten gezeigt wird, wenn nicht irgendein Mangel oder Bedürfnis vorliegt. „Wunschlose Glücklichkeit“ macht also träge. Ebenfalls kommt es nicht zu einem Verhalten, wenn keine entsprechende Gewohnheit vorliegt.
Die Vorhersagen aus Hulls Hypothesen bestehen nicht in Versuchen
Hulls Theorie sagt also voraus, dass die Art des Bedürfnisses egal ist und nur die Summe der Stärke der Bedürfnisse von Bedeutung ist und einen Trieb bilden, dessen Verringerung die Verstärkung des Verhaltens ausmacht. Daraus folgt, dass dasselbe Verhalten gezeigt werden müsste, egal, ob ein Tier hungrig oder durstig ist.
Überprüft wurde das in einem Experiment im Jahr 1949, in dem Tiere konditioniert wurden, einen Schalter zu bedienen: Den Schalter nach rechts bewegen wurde mit Futter verstärkt wurden, so, wie wir es bereits aus den Skinner-Versuchen kennen. Dann wurden die Tiere in drei Gruppen aufgeteilt und die Löschungsresistenz des Hebeldrückens unter verschiedenen Bedingungen getestet. Einer Gruppe wurde über einen Zeitraum Wasser, der anderen Nahrung und der Kontrollgruppe nichts von beidem vorenthalten. Auf diese Weise hatte die Kontrollgruppe keinen gesteigerten Trieb, während der Trieb der beiden anderen Gruppen gleich groß sein müsste, auch wenn unterschiedliche Bedürfnisse, nämlich Hunger und Durst, zu Grunde liegen.
Hulls Theorie sagt nun voraus, dass die Kontrollgruppe kein Hebeldrücken zeigt, weil kein Trieb vorliegt, während die beiden anderen Gruppen die gleiche Triebstärke aufweisen und ein entsprechend löschungsresistentes Verhalten zeigen müssten.
Tatsächlich stellt auch die Kontrollgruppe das Verhalten am schnellsten ein. Allerdings besteht ein großer Unterschied zwischen den beiden anderen Gruppen: Die hungrige Gruppe versucht viel länger, durch Hebeldrücken an Futter zu kommen.
Warum sind wir nun auf Hull eingegangen?
Der geneigte Leser könnte nun fragen, warum Hull so viel Text gewidmet wird, wenn ein Großteil seiner Annahmen nicht bewiesen oder gar widerlegt werden konnte. Die Antwort darauf ist, dass er unser Bewusstsein in Richtung der Bedürfnisse lenkt: Genau die Tatsache, dass im Experiment auf Grund seiner Theorien gezeigt wurde, dass die Wirksamkeit einer Verstärkung an ein bestimmtes biologisches Bedürfnis und seine Ausprägung oder Stärke gekoppelt sein kann, sollten wir uns merken, denn von diesem Punkt aus wurden weitere Ansätze entwickelt, die vor allem denjenigen schmecken werden, die der Meinung sind, dass ein Hund nicht nur für Futter folgen soll.
Klar ist aber, dass damit nicht erklärt werden kann, warum im Tierversuch auch der nährstofffreie Süßstoff Saccharin als Verstärker wirksam war: Schließlich hat dieser keine biologische Wirksamkeit, weil er den Organismus nicht ernährt. Als Randbemerkung sei gesagt, dass hiermit auch nicht die Wirksamkeit von Drogen wie Alkohol als Verstärker erklärt werden kann, da diese schließlich sogar ein biologisches Risiko darstellen. Beide Phänomene bleiben für uns ungeklärt, zumal wir unsere Tiere nicht mit der Gabe von Drogen verstärken möchten.
Ein weiterer Aspekt ist, dass Hull seine Theorie mehrfach erweiterte. Unter anderem fasste er später die Definition der Triebe weiter: Es wurde, vor allem anhand menschlichen Verhaltens, erkannt, dass nicht alle Triebe rein physiologischen Bedürfnissen wie dem nach Nahrung geschuldet sind. Bedenken wir, dass man Geld nicht essen kann und es deshalb nicht unmittelbar den durch Hunger ausgelösten primären Trieb befriedigen kann, wundert es, dass wir dennoch bereit sind, fast alles für Geld zu tun. Um diesen Umstand an die Theorie der Bedürfnisse und Triebe anzupassen, führte Hull die Unterscheidung zwischen primären Bedürfnissen und Trieben einerseits und sekundären Bedürfnissen und Trieben andererseits ein.
Um beim Geld zu bleiben, scheint das Bedürfnis nach selbigem in einigen Fällen daher zu rühren, dass eine Assoziation zwischen der Befriedigung primärer Bedürfnisse und beispielsweise Geld hergestellt wurde: Wir haben gelernt, dass wir für Geld Nahrung kaufen und somit die primären Bedürfnisse und damit den primären Trieb senken können. Da bekanntermaßen die Triebreduktion verstärkend wirkt, ist es von der Unterscheidung zwischen primären und sekundären Trieben zur modernen Unterteilung der Verstärker in primäre und sekundäre, der wir im weiteren auch noch unserer Aufmerksamkeit widmen werden, nur ein kleiner Schritt. Die folgende Tabelle stellt primäre uns sekundäre Triebe nochmals zur exakten Unterscheidung gegenüber:
| Primäre Triebe... | Sekundäre Triebe... |
| ...basieren auf biologisch/physiologischen Bedürfnissen wie der Linderung von Hunger, Durst, Schmerz etc. | ...basieren NICHT auf biologisch/physiologischen Bedürfnissen wie der Linderung von Hunger, Durst, Schmerz etc. |
| ...sind angeboren. | ...sind nicht angeboren. |
| ...müssen nicht erlernt werden. | ...sind erlernte Assoziationen zu einem primären Trieb. |
Von der Triebreduktion als Verstärkung zum Premack-Prinzip der Verhaltenswahrscheinlichkeit
Gehen wir zunächst weiter davon aus, dass der Ausgleich biologisch-physiologischer Bedürfnisse wie Durst oder Hunger die Wertigkeit eines Verstärkers ausmachen. Dann stellt sich aber die Frage, ob die bisherige Ansicht, Wasser oder Nahrung als Reiz die Verstärkung auslösen, korrekt ist. Oder liegt die Verstärkung nicht vielmehr in der folgenden Reaktion, die wir „Trinken“ oder „Fressen“ nennen? Schließlich wird das Bedürfnis nur durch das entsprechende Verhalten gemindert.
Diesen Gedankengang führte F. D. Sheffield 1948 in Feld, und er ist weitreichend, denn mit der Idee, dass ein Verhalten oder Handlung für eine vorangehende Verhaltensweise verstärkend wirkt, öffnen sich ganz neue Möglichkeiten der Verstärkung, deren Gesetzmäßigkeiten der 1925 geborene US-Psychologe David Premack erforschte und 1962 in dem nach ihm benannten Premack-Prinzip zusammenfasste.
Das Premack-Prinzip der unterschiedlichen Auftrittswahrscheinlichkeiten
Das Premack-Prinzip zielt darauf, Skinners positive Verstärkung und Bestrafung innerhalb seines Kontingenzschemas, in dem es immer um Reize und Wahrnehmungen als Handlungsfolge ging, so umzuformulieren, dass nun keine Reize, sondern Verhaltensweisen die Konsequenzen von Handlungen sind.
Dazu geht er davon aus, dass jedes Individuum, wenn es frei entscheiden kann, verschiedene Verhaltensweisen in unterschiedlicher Menge zeigt. So ergeben sich, wissenschaftlich gesprochen, unterschiedliche Auftrittswahrscheinlichkeiten, Baseline oder Basisraten für die verschiedenen Handlungen.
Das Premack-Prinzip sagt nun für die positive Verstärkung, dass ein Verhalten mit niedrigerer Auftrittswahrscheinlichkeit positiv verstärkt wird, wenn in Folge dessen eines mit höherer Auftrittswahrscheinlichkeit gezeigt werden kann oder darf.
Die Kernaussage Premacks ist also, dass unterschiedliche Auftrittswahrscheinlichkeiten definieren, welches Verhalten verstärkend wirkt (das wahrscheinlichere) und welches damit verstärkt werden kann (das unwahrscheinlichere).
Daraus ließe sich schließen, dass eine positive Bestrafung erreicht werden kann, indem ein weniger wahrscheinliches Verhalten als Folge eines wahrscheinlicheren Verhaltens ausgeführt werden muss. Ob das tatsächlich so ist, stellt werden wir noch beleuchten.
Das Premack-Prinzip im Experiment von 1963
David Premack selbst führte 1963 ein Experiment an einem Affen namens Chicko durch, für den ein Raum so präpariert wurden, dass er dort entweder gar nichts tun konnte oder einen Hebel drücken oder eine Tür öffnen oder an einem Kolben ziehen konnte.
Zunächst ermittelte Premack, die Baseline, die angibt, wie wahrscheinlich ein Verhalten vor einem Experiment ist, für jede der drei Verhaltensweisen: Der Affe konnte sich frei entscheiden, wie oft er in einer gewissen Zeitspanne den Hebel drückte, die Tür öffnete und an dem Kolben zog. Dabei stellte sich heraus, dass er sehr selten am Kolben zog, öfter die Tür öffnete und am häufigsten den Hebel drückte. Daraus ergibt sich die Wahrscheinlichkeitsskala:
Nun wurde in mehreren Sitzungen die Zugänge zu diesen Handlungsmöglichkeiten so konfiguriert, dass immer erst eine der Handlungen vor jeweils einer anderen erfolgen musste. Dieses Verhältnis der Handlungen untereinander wird als Kontingenzbeziehung bezeichnet. In der folgenden Tabelle sind die Ergebnisse zusammengefasst, wobei in der Spalte „Kontingenzbeziehung“ die jeweils häufiger gezeigte Verhaltensweise in grün, die niedrigere in rot markiert ist.
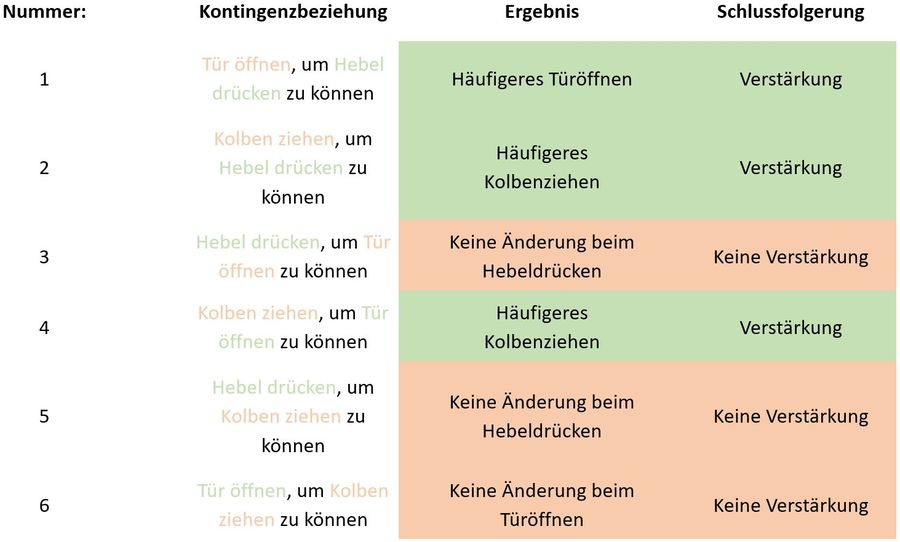
scheinlicheren (grüne Schrift) ist, nimmt im Ergebnis die Auftrittswahrscheinlichkeit der unwahrscheinlichere zu. Die Schlussfolgerung ist,
dass das wahrscheinlichere Verhalten als Verstärker für das unwahrscheinlichere dient.
Aus dem Experiment geht klar hervor, dass immer dann, wenn eine weniger wahrscheinliche Handlung als Voraussetzung für eine wahrscheinlichere (Fälle 1,2 und 4) verlangt wurde, die weniger wahrscheinliche an Häufigkeit zunahm. Die wahrscheinlichere Handlung als Folge der unwahrscheinlicheren diente also wie ein Verstärker.
Das Premack-Prinzip und die ersten weiterführende Fragen
Interessant ist, dass schon Premack in weiteren Experimenten erkannte, dass eine Verstärkung nur dann erfolgte, wenn die wahrscheinlichere Verhaltensweise durch Einschränkungen des Verstärkerplans verringert wurde.
Wenn, wie in Zeile 4 der Tabelle, die Anzahl des Kolbenziehens erhöht und diese Erhöhung durch Türöffnen verstärkt werden soll, sollte ein Verstärkerplan gewählt werden, dessen Quote ein anderes Verhältnis als 4/8 widergibt, da 4 Mal Kolbenziehen und 8 Mal Türöffnen der Baseline entspricht. Ist das Ziel nun, dass das Verhalten „Kolbenziehen“ öfter gezeigt wird als bisher, muss mindestens 5 Mal der Kolben gezogen werden, um 8 Mal die Tür öffnen zu dürfen. Alternativ könnte auch der Zugang zur Verhaltensweise „Tür öffnen“ reduziert werden, sodass für 4 Mal Kolbenziehen nur noch 7 Mal die Tür geöffnet werden kann.
Diese Erkenntnis erforderte weitere Forschung, um sie in eine Theorie eingliedern zu können. Premack aber hielt daran fest, dass die Auftrittswahrscheinlichkeit ein ausschlaggebendes Element sei und versuchte über allerlei Argumentationen, den Kern seiner Hypothese zu bewahren, während die Forscher Timberlake und Allison, wie wir sehen werden, eine Folgethese aufstellten.
Alltagsbeispiele des Premack-Prinzips und weitere Fragen
Dessen ungeachtet, stellen wir, wenn wir unser eigenes Verhalten beobachten, fest, dass auch wir einige Aktivitäten häufiger zeigen, und damit scheinbar lieber machen, als andere: Beispielsweise habe ich während meiner Schulzeit häufiger gespielt, als ich TV geschaut habe. Das habe ich aber wiederum häufiger getan, als zu lernen. Meine Wahrscheinlichkeitsskala sah also so aus:
Meine Eltern haben sich, auch ohne das Wissen um Premacks Forschung, diesen Umstand zu Nutze machen wollen, indem sie die Regel durchsetzten, dass ich erst meiner Lieblingsbeschäftigung, dem Spiel, nachgehen durfte, wenn ich vorher gelernt hatte, nach dem altbekannten Motto erst die Arbeit, dann das Spiel. Das hat sehr gut geklappt, sodass das Spielen meine Lernaktivitäten verstärkte. Allerdings war zu beobachten, dass diese Verteilung nicht an allen Tagen gleich war, sondern hin und wieder Fernsehen und Spielen die Rollen tauschten.
Das hat auch Premack in seinen Experimenten schon bemerkt. Natürlich suchte er nach einer Erklärung für diesen Rollentausch ebenso, wie nach einer Lösung dafür, dass in diesen Zeiten auf Grund seiner Hypothese nun nicht mehr so trainiert und konditioniert werden kann, wie im Allgemeinen.
Allerdings ist es nach Premack nicht möglich, die wahrscheinlichere Verhaltensweise des Spielens mit der weniger wahrscheinlichen des Lernens zu steigern. Stattdessen könnte man auf die Idee kommen, dass eine weniger häufige Verhaltensweise in Folge einer häufigeren einer positiven Strafe nahekommt.
Wenn Ihr Euch fragt, ob es überhaupt nötig ist, eine häufigere Verhaltensweise mit einer weniger häufigen zu bestärken, dann gebe ich Euch hier kurz ein Beispiel, in dem wir davon ausgehen, dass die Verhaltensweisen, die wir besonders oft zeigen, die häufig unsere Lieblingsbeschäftigungen sind, im Vergleich zu allen anderen Verhaltensweisen besonders gut ausführen. Vielleicht, weil wir diese Verhaltensweisen oft ausführen und somit üben. Stellt Euch vor, statt zu spielen wäre ich sehr häufig Tennisspielen gegangen. Nehmen wir weiter an, dass Tennisspielen die Aktivität ist, die ich am besten beherrsche und die damit meine größte Stärke darstellt. Wenn ich sie nun auch besser, als viele andere beherrsche und meine Eltern denken, ich sollte mich beruflich mit Tennisspielen beschäftigen, müsste diese Verhaltensweise weiter verstärkt werden. Die Frage ist aber nun: Womit? Im Rahmen von Premacks Prinzip wird das über keine andere Verhaltensweise als Verstärker funktionieren, wodurch in vielen Fällen ein Ausbau von Stärken, also Verhaltensweisen, die sehr gut beherrscht und am häufigsten gezeigt werden, nicht möglich wäre.
Die Hypothese von Timberlake und Allison nahm sich nun also der Frage an, ob auch Verhaltensweisen, die wir als "Stärken" bezeichen können, weiter verstärkt werden können und wenn ja, womit und warum.
Die Hypothese über die Verhaltenseinschränkung oder Verhaltensdeprivation
William Timberlake und James Allison befassten sich in den frühen 1970er Jahren mit der Frage, ob das Premack Prinzip empirisch haltbar ist. Auf Grund vieler Experimente anderer Wissenschaftler, sowie eigener und der beiden gerade aufgekommenen Fragen zweifelten sie, ob der Unterschied in der Auftretenswahrscheinlichkeit zweier Verhaltensweisen ausschlaggebend für die Aufteilung in verstärkbares oder konditionierbares Verhalten einerseits und verstärkendes Verhalten andererseits ist.
Die Entwicklung der Hypothese von der Verhaltensdeprivation
Ähnlich wie Premack, messen auch Timberlake und Allison zunächst die Baseline bzw. die Basisrate von Verhalten. Im Unterschied zu Premack betrachten sie allerdings immer zwei Verhaltensweisen, deren Auftreten unter freien Bedingungen sie zählen. Freie Bedingungen meint, dass ein Versuchstier über einen längeren Zeitraum in einer Skinner-Box zwei Verhaltensweisen ohne weitere Einschränkung und somit in der Verteilung frei zeigen kann, beispielsweise Trinken und in einem Laufrad laufen. Hieraus ergibt sich eine gepaarte Baseline für die beiden Verhaltensweisen, wobei es egal ist, in welchen Maßeinheiten die beiden Verhaltensweisen gemessen werden. Denkbar wäre für beide eine Zeit zu messen. Es wäre aber auch möglich, die Umdrehungen des Rades zu messen und die getrunkene Wassermenge oder die Häufigkeit des Wasserschluckens.
Denkbar wäre eine Baseline-Messung wie in der folgenden Tabelle dargestellt. Aus ihr wird auch klar, dass eine Ratte über eine Zeit von 20 Minuten auch andere Verhaltensweisen zeigte, die aber nicht gemessen wurden.
| Maßeinheit | Wassertrinken | Laufradlaufen |
| Minuten pro Stunde | 15 | 30 |
Timberlake und Allison sagen nun, dass ein wirksamer Verstärkerplan, der eine der beiden Verhaltensweisen in der Menge steigen lässt und die andere Verhaltensweise als Verstärker nutzt, so angelegt sein muss, dass der Zugang zur verstärkenden Verhaltensweise eingeschränkt ist: Zeigt der Proband das zu vermehrende Verhalten in der Menge der freien Basisrate, muss die Zugriffsmöglichkeit auf die verstärkende Verhaltensweise so beschränkt sein, dass diese unter die Basisrate sinkt. In seinem Bestreben, beide Verhaltensweisen mindestens in der Menge der Basisrate zeigen zu können, wird er eine der beiden Verhaltensweisen öfter zeigen, bis er auch die zweite in der Basisline-Menge gezeigt hat.
Mit dieser Annahme kann nun also entschieden werden, ob ein Verstärkerplan erstellt werden soll, der entweder das Wassertrinken vermehren soll, was mit Laufradrennen verstärkt würde. Ein solcher Plan wäre dann auch über das Premack-Prinzip erklärbar.
Interessanter ist aber ein Plan, der das unwahrscheinlichere Wassertrinken als Verstärker für das Laufradlaufen verwendet. Dazu müsste der Plan so erarbeitet werden, dass nach 30 Minuten im Laufrad der Zugang zum Wasser weniger als 15 Minuten lange gewährt wird. Würde beispielsweise nach 10 Minuten im Laufrad statt 5 Minuten, was der Baselineverteilung entspräche, nur 2,5 Minuten lang die Möglichkeit zu trinken ermöglicht, ergäbe sich folgende Tabelle:
Verhaltensweise verändert, kann diese als Verhaltensverstärker für die wahrscheinlichere verwendet werden.
Die Tabelle veranschaulicht, dass die Ratte nun insgesamt 60 Minuten statt 30 Minuten im Laufrad verbringen muss, um das Verhalten „Trinken“ 15 Minuten lang zeigen zu können.
Nun könnte argumentiert werden, dass es sich so verhält, weil Laufradrennen durstig macht. Timberlake und Allison haben selber aber Experimente durchgeführt, in denen die beiden Verhaltensweisen sich weit ähnlicher waren: Die Tiere bekamen die Wahlmöglichkeit, zwei unterschiedlich starke Zuckerlösungen zu trinken. Das Ergebnis war aber dasselbe, wie in unserem Beispiel: Die Baselines von „Trinken der Lösung A“ und die von „Trinken der Lösung B“ waren unterschiedlich. Wurde Verhaltensweise A in einem Verstärkerplan so eingeschränkt, dass die Verhaltensweise B die Voraussetzung für A wurde, nahm Verhaltensweise B zu und umgekehrt.
Die Ähnlichkeit zum Konzept des Inneren Milieus
Im Grunde ähnelt meines Erachtens das Prinzip der Verhaltensdeprivation in der Grundannahme der Annahme eines inneren Milieus, bei dem verschiedene Kriterien (Nahrung, Flüssigkeit, Müdigkeit etc.) jeweils ausgeglichen und in einem Sollwert zu halten sind: Gerät einer der Parameter des inneren Milieus aus dem Gleichgewicht, entsteht ein Bedürfnis, das durch eine Handlung ausgeglichen werden muss. Diese Handlung ist dann der äußere Ausdruck des Bedürfnisses, das nicht nur rein biologischer Natur sein muss. Langeweile kann ebenfalls ein Bedürfnis auslösen.
Im Durchschnitt kann sicherlich davon ausgegangen werden, dass zum Ausgleich des inneren Milieus in einer gewissen Zeiteinheit, sei es eine Stunde oder ein Tag, ähnlich starke Bedürfnisse pro Kriterium entstehen: Der Körper braucht eine ähnliche Menge Flüssigkeit am Tag und eine gewisse Menge Nährstoffe, um bei einfachen und klaren Beispielen zu bleiben.
Daraus folgt eine gewisse Wahrscheinlichkeitsverteilung der entsprechenden Handlungen, die ja mit dem Ziel ausgeführt werden, je ein Bedürfnis auszugleichen. Natürlich sind das außerhalb der Laborbedingungen immer weit mehr als nur zwei, die in Konkurrenz zueinanderstehen und entsprechend das innere Milieu abbilden.
Wenn wir also in einem Verstärkerplan eine Handlung einschränken und eine andere zur Vorbedingung machen, schränken wir auch die Möglichkeit des Bedürfnisausgleichs einer der Handlungen ein. Die zu konditionierende Handlung wird dadurch nicht mehr nur so lange ausgeführt, bis das ihr zugrunde liegende Bedürfnis ausgeglichen ist, sondern bis das hinter der Verstärker-Handlung stehende Bedürfnis ausgeglichen ist.
In der 1974 erschienen Arbeit der beiden wurde das natürlich nicht besprochen. Sie waren damals voll und ganz darauf konzentriert, den Unterschied zwischen Premacks Ansatz und dem eigenen der Verhaltensdeprivation herauszuarbeiten und klarzustellen, dass es den Premacks gar nicht mehr bedarf. Dazu war die Analyse vieler schon von anderen als auch eigener Experimente nötig, aus denen sie dann Formeln ableiteten.
Vor diesem Hintergrund haben sie sich auch nicht damit beschäftigt, Ihr Konzept griffiger darzustellen. Allerdings scheint der Ansatz des Behavioral Bliss Points, dem wir uns nun zuwenden, nichts anderes zu sein, als eine einfache und griffigere Darstellung des Konzepts der Verhaltensdeprivation oder -einschränkung.
Der Behavioral Bliss Point oder die Koordinaten der Zufriedenheit
Der Ansatz des Behavioral Bliss Points ist meines Erachtens nach nicht mehr, als ein griffiger Name und eine einfache Darstellung dessen, was Timberlake und Allison erdacht haben. Sicherlich konnte sich diese Vereinfachung etablieren, nachdem die Grundannahme der Verhaltensdeprivation allgemein anerkannt wurde. Wer sie erdacht hat, konnte ich nicht recherchieren.
Wie sieht der Ansatz genau aus?
Auch hier werden nämlich zwei Verhaltensweisen betrachtet, für die im ersten Schritt die Baseline, also die Basisrate unter freier Entscheidung des zu konditionierenden Wesens gemessen. Im nächsten Schritt wird ein Koordinatensystem mit je einer Achse für die Auftrittsmenge der beiden Verhaltensweisen gezeichnet. Wir bleiben bei unserem obigen Beispiel, in dem eine Ratte in einer Stunde 15 Minuten lang trinkt und sich 30 Minuten im Laufrad betätigt. Damit ist der Bliss-Point genau dort (im Diagramm mit X gekennzeichnet) einzutragen. Weitere 15 Minuten verbringt die Ratte mit anderen Aktivitäten, die unbeachtet bleiben. Vereinfachend können wir auch sagen, dass sie in 45 Minuten 30 Minuten läuft und 15 Minuten trinkt.
Die durch den Bliss-Point laufende grünen Gerade verdeutlicht das Verhältnis der beiden Verhaltensweisen auf niedrigeren Zeiteinheiten: Betrachten wir nur 15 Minuten, wird sie davon 10 Minuten laufen und 5 Minuten trinken.
Jeder Punkte, der nicht auf der grünen Geraden liegt, dürckt ein Missverhältnis zwischen den beiden Verhaltensweisen aus. So lässt sich jeder Verstärkerplan, der mit Koordinaten ausgedrückt werden kann, die unterhalb oder rechts der blauen Geraden liegen, Laufen zum Verstärker für Trinken werden. Beispielsweise wäre das Laufrad in dem roten Punkt X1 nach 15 Minuten Trinken nur für 15 anstatt für 30 Minuten verfügbar. Um die vollen 30 Minuten laufen zu können, muss die Ratte nun weitere 15 Minuten trinken. Ergo steigt die Performance des Verhaltens „Trinken“.
Umgekehrt verhält es sich im roten Punkt X2. Dort verstärkt Trinken das Verhalten Laufen, weil nach 30 Minuten laufen nicht volle 15, sondern nur 10 Minuten lang getrunken werden kann. Möchte die Ratte weitere 5 Minuten trinken, muss sie erneut aufs Laufrad.
Die aktuelle Einteilung der Verstärkerarten
Nun haben wir die Grundlagen für die moderne Einteilung der Verstärker weitestgehend erläutert, wobei wir die Verstärkerarten, die für die tierische Konditionierung unwesentlich sind, nicht beachten.
Primäre und sekundäre Verstärker
Wir haben von Primären und Sekundären Trieben gehört, die Hull danach unterscheidet, ob sie angeboren (primär) oder gelernt (sekundär) sind. Dieser Denkansatz ist auch auf die Verstärker übertragen worden: Futter deckt ein primäres Bedürfnis und wäre entsprechend den primären Verstärkern zuzuordnen. Ein lobendes Wort wie „suuupiii“ oder ähnliches gehört zu den gelernten sekundären Verstärkern: Diesem Lobwort folgt meist ein primärer Verstärker wir Futter. Die Assoziation zwischen beiden entspricht der klassischen Konditionierung Pawlows.
Verhalten verstärkt primär, der Reiz nur sekundär
Außerdem hat sich David Premack von Hull dazu inspirieren lassen, dass weniger ein Reiz die Verstärkung bringt, als das dem Reiz folgende Verhalten. Insofern wird der Reiz des Lobwortes oder des Klickers zu einem Hinweisreiz für den eigentlichen Verstärker und dadurch zu einem sekundären Verstärker. Daraus haben wir nun schließen können, dass ein Verhalten ein anderes verstärkt. Nach den Forschungen von Timberlake und Allison wissen wir nun, dass jeweils das Verhalten, das eingeschränkt wird, ein anderes verstärkt.
Als nächstes müssen wir noch einmal kurz auf die Kontiguität und die Kontingenz eingehen. Sie stehen für die zeitliche Verzögerung zwischen Reizen und Reaktionen und für die Vorhersagekraft, die Reize und Reaktionen für einander haben und deren Bedeutung im Hundealltag nicht zu unteschätzen ist. Dazu greifen wir nochmals auf Skinner zurück.
Skinners abergläubische Tauben – Warum es beim Loben des Hundes auf Schnelligkeit ankommt
Dass es bei der Hundeerziehung und im Training darauf ankommt, das gewünschte Verhalten schnell zu markieren und zu loben, liegt nicht daran, dass Hunde ein schlechtes Gedächtnis haben. Es liegt vielmehr daran, dass sie bei schlechtem zeitlichen Bezug zwischen Verhalten und Lob einen Aberglauben entwickeln können, welches Verhalten die Konsequenz auslöste. Skinners Tauben-Experiment belegt dies.
Skinners abergläubische Tauben
Der Zusammenhang zwischen zeitlicher Nähe und verlässlicher Vorhersagekraft, der Reize mit Reizen im Falle der klassischen und mit Reaktionen im Falle der operanten Konditionierungen verbindet, wurde schon im ersten Abschnitt über Pawlow und im dritten zu Skinners Kontingenzschema erwähnt. Er ist aber so ausschlaggebend, dass ich hier nochmals auf beide Aspekte gesondert eingehen werde.
Auch Skinner wollte, nachdem er das Kontingenzschema und die ersten Verstärkerpläne entwickelte hatte, durch Experimente erforschen, wie sich wiederkehrende Verstärkung auf Verhalten auswirkt, wenn tatsächlich der Zusammenhang zum Verhalten nicht erkennbar ist. Im Experiment erreichte er das, indem es gar keinen Zusammenhang gab.
Das Experiment zum Aberglauben
Zu diesem Zwecke setzte er seine Versuchstiere in eine Skinner-Box, die so konfiguriert war, dass sie unabhängig vom Verhalten der Tiere hin und wieder Futter als Verstärkung freigab.
Skinner konnte nun beobachten, dass die Tiere das Verhalten, das sie kurz vor einer Futterfreigabe zeigten, danach häufiger zeigten. Dadurch wiederum stieg die Wahrscheinlichkeit, dass das Verhalten zufällig erneut von einer verstärkenden Futtergabe gefolgt wurde. Im Laufe der Zeit entwickelte jedes Tiere sein ganz persönliches abergläubisches Verhalten: Es wurden Flügel ausgestreckt, auf einem Bein gestanden und alle möglichen anderen Verhalten. Alleine eines einte sie: Sie hatten alle keine Auswirkung auf den (vielleicht) folgenden Reiz.
Warum ist Aberglauben ein wichtiges Thema?
In Skinners Experiment wurde klar gemacht, dass sich auf Grund mangelnder Kontingenz Aberglaube entwickeln kann. Nun müssen wir nochmal kurz klarstellen, was Kontingenz meint. Hierbei handelt es sich um eine Verbindung zwischen Reizen und als Reaktionen bezeichnetem Verhalten. Ist diese Verbindung tatsächlich gegeben, soll oder kann ein bestimmter Reiz eine bestimmte Reaktion und diese einen weiteren spezifischen Reiz hervorrufen. Das gelingt nur, wenn in der Reiz-Reaktions-Kette den einzelnen Elementen eine verlässliche und tatsächliche Vorhersagekraft innewohnt und diese auch als solche erkannt wird.
Dabei können die Reize Hinweisreize (z. B. Kommando für Sitz) und die gewünschte Reaktion (Hund setzt sich) sein. Bedenken wir nun die Erkenntnisse über Verstärker, folgt dieser gewünschten Reaktion (Sitz-Position einnehmen) ein Reiz als primärer (Anblick von Futter) oder sekundärer Verstärker, (Klick oder Lobwort, das verlässlich den Anblick oder die Verfügbarkeit des primären Verstärkers ankündigt), wobei dieser Reiz (der Anblick oder der Klick) wiederum als Hinweisreiz verstanden werden kann: Er ist mit der Reaktion verbunden, die tatsächlich verstärkenden Charakter hat: dem Fressen im aktuellen Beispiel.
So betrachtet, wird schnell klar, dass wir es uns kaum leisten können, dass in eine solche Reiz-Reaktionskette ein Aberglaube Einzug hält, denn ein solcher würde nicht zu dem von uns gewünschten Ergebnis führen.
Nun stellt sich die Frage, was auf die Erkennbarkeit der Vorhersagekraft Einfluss hat? Es scheinen vor allem zwei Faktoren zu sein:
- Die Regelmäßigkeit oder Konsequenz. Z. B. kann ein Lebewesen durch einen Verstärkerplan mit Immerverstärkung schnell die Assoziation zwischen einem Verhalten und der Verstärkung herstellen.
- Die Kontiguität, der wir uns im nächsten Absatz widmen.
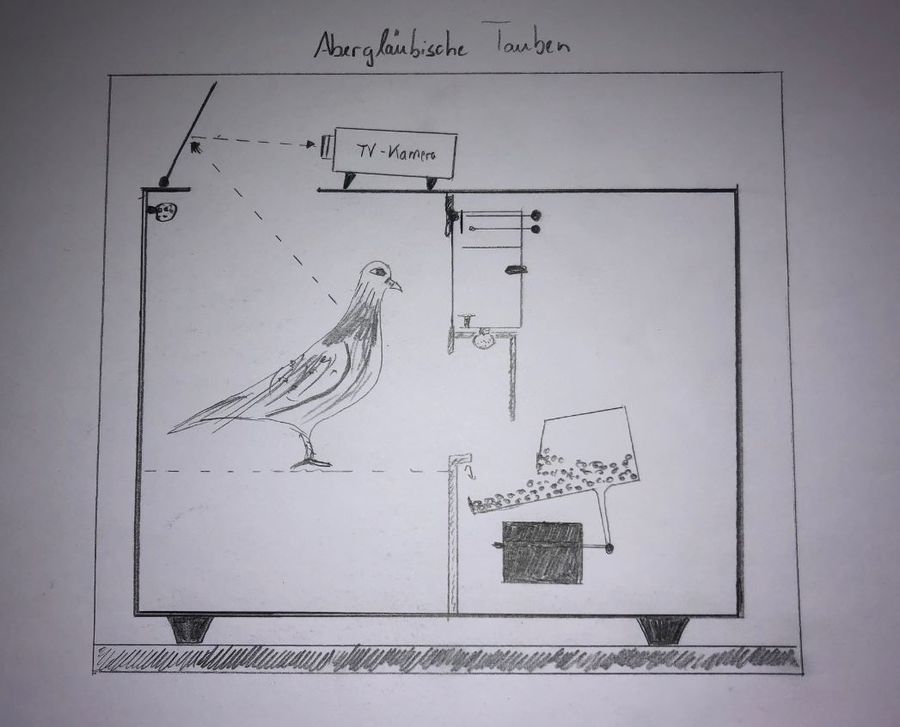
Kontiguität: Das richtige Timing verringert zeitweiligen Aberglauben
Die Wissenschaft versteht unter Kontiguität die räumliche und zeitliche Nähe eines Reizes und einer Reaktion. Schon Pawlow stellte fest, dass das short-delayed-conditioning sich als besonders effiziente Abfolge von Reizen für die Kopplung zweier Reize, also die klassische Konditionierung, eignet.
Anzunehmen ist, dass es sich in der instrumentellen Konditionierung, bei der ein Reiz mit einer Reaktion gekoppelt werden soll, bezogen auf ein Verhalten und den folgenden Reiz als Verstärker, ähnlich verhält.
Forschung zu Kontiguität
Das Thema Kontiguität hat im letzten Jahrhundert einige Forscher beschäftigt. Einige, wie Robert Rescorla 1968, erforschten, ob die Kontiguität oder die Kontingenz der wesentlichere Faktor ist, allerdings bezogen auf die klassische Konditionierung. Da diese Forschung aber den Rahmen sprengen würde, konzentrieren wir uns auf die einfacheren Experimente, die sich damit befassen, wie die zeitliche Nähe von Reaktion/Handlung und Verstärkung sich in der instrumentellen Konditionierung auswirken.
Aufbau eines Experiments zur Kontiguität
Es wird auch hier wieder das Verhalten von Ratten in einer Skinner-Box beobachtet. Die Box ist so konfiguriert, dass die Ratten auf das Drücken eines Hebels konditioniert werden sollen und das Verhalten mit Futter aus einem Futterspender verstärkt werden soll. Das Besondere bei dieser Versuchsreihe war, dass die Skinner-Box für die verschiedenen Versuchsgruppen, in die die Tiere eingeteilt wurden, jeweils so eingestellt war, dass das verstärkende Futter mit einer anderen zeitlichen Verzögerung der Reaktion folgte.
Im Ergebnis konnte gemessen werden, dass Akquisitionsrate, also die Geschwindigkeit, mit der das gewünschte Verhalten des Hebeldrückens aufgebaut wurde, extrem abnahm, sobald die Verstärkung mit einer geringen Verzögerung von nur wenigen Sekunden erfolgte.
Schlussfolgerungen aus dem Experiment
Heute geht man davon aus, dass diese Abnahme der Lerngeschwindigkeit nicht darauf zurückzuführen ist, dass die Tiere sich nicht mehr an ihre Handlung erinnern. Vielmehr wird ein Lebewesen in der Zeit zwischen einem bestimmten Verhalten und einer Konsequenz nicht still abwarten, sondern weitere Verhaltensweisen an den Tag legen. Je mehr Zeit nun zwischen Reaktion und Verstärkung vergeht, desto mehr unterschiedliche Handlungen können vollzogen werden. Welche davon hat denn die Verstärkung ausgelöst? Das ist die Frage, die richtig zu beantworten immer schwerer wird, je länger die Verzögerung ist.
Wenn wir uns nun erinnern, dass Kontingenz bedeutet, dass eine Handlung klar einen Reiz (der ein Verstärker sein kann) vorhersagt, ist auch klar, dass ein Lebewesen diese Vorhersagekraft dann schneller erkennt, wenn das Verhältnis zwischen beiden zeitlich klar einzugrenzen ist.
Grundlagen zu Bestrafungen & der Wirkung aversiver Verhaltenskontrolle
Die Frage, ob der Einsatz von Bestrafungen, aber auch der negativen Verstärkung, in der Hundeerziehung eine Berechtigung haben, spaltet die Gemeinschaft der Hundehalter. Die auf den Risiken gründenden Argumente der Strafgegner werden nirgends klarer als in der folgenden Beschreibung der wissenschaftlichen Erkenntnisgewinnung.
Warum über Strafen schreiben?
Seit wir Skinners aus vier Feldern bestehendes Kontingenzschema kennengelernt, haben, haben wir uns fast ausschließlich mit einem davon beschäftigt: Alles seither bezog sich primär auf die positive Verstärkung. Das ist ein Indiz für die Wichtigkeit, der positiven Verstärkung. Dennoch dürfen wir die beiden Bestrafungsarten nicht vernachlässigen, sondern müssen sie mit Themen wie Hinweisreizen, Verstärkerplänen, zeitliche Nähe oder Kontiguität und daraus folgende Kontingenz, also Vorhersagekraft verknüpfen. Dies wird uns auch zur gelernten Hilflosigkeit führen, an der wir nochmals einen Berührungspunkt zum vierten und letzten Feld, der negativen Verstärkung, haben werden. Damit sind die drei Felder, die zur aversiven Verhaltenskontrolle zusammengefasst werden können, angeschnitten. Insgesamt wird der geneigte Leser schon bei der Lektüre des nun Folgenden erkennen, dass er tunlichst mit der positiven Verstärkung auskommen sollte.
Effektivität positiver Bestrafung
Skinner und sein Doktorand Estes verwendete in seinen Experimenten ausschließlich leichten Strom als aversiven Bestrafungsreiz. Aus den Ergebnissen der Experimente zur positiven Bestrafung schlossen sie, dass Bestrafungen wenig effektiv seien, um eine langfristige Verhaltensänderung zu bewirken und den Vorgang der Löschung nachhaltig zu beschleunigen.
Im letzten Jahrhundert wurde Frage, ob und wenn ja wann positive Strafen effektiv sein können, in diversen Tierversuchen weiter untersucht.
Die Stärke des Strafreizes ist eine wesentliche Einflussgröße
In einer Arbeit über die langfristigen Effekte von Bestrafungen während der Verhaltenslöschung, die Erling E. Boe und Russell M. Church 1967 veröffentlichten, stellten die beiden experimentell fest, dass die Intensität des aversiven, als Strafe dargereichten Reizes für die Effektivität der Strafe entscheidend ist.
Für das Experiment wurden 60 Ratten in Gruppen zu je 10 Ratten aufgeteilt. Um ein zu löschendes und zu bestrafendes Verhalten mit einer stabilen Reaktionsrate zu erzeugen, wurden sie in einer Skinner-Box mit Futter während 4 einstündiger Sessions positiv konditioniert, einen Schalter zu drücken. In der letzten wurde für jede Ratte die Summe der Reaktionen, also die Summe des Schalterdrückens, festgehalten. Im Durchschnitt waren das 722 Betätigungen des Schalters pro Stunde und Ratte.
In der nun folgenden Löschungsphase wurden die Ratten nicht mehr nur nicht verstärkt, sondern zwischen der sechsten und einundzwanzigsten Minute der ersten von 9 einstündige Sitzungen mit Stromschlägen durch den leitfähigen Boden der Box bestraft. Die Stromstärke der Schocks lag dabei, je nach Gruppe, bei 35, 50, 75, 120 oder 220!! Volt. Die Kontrollgruppe, im Diagramm mit "Control" bezeichnet, bekam gar keine Bestrafung. In jeder der 60-minütigen Löschungssitzungen wurde für jede Ratte festgehalten, wie häufig sie in Summe den Schalter betätigte.
Nun berechneten die Forscher für jede Ratte und für jede der Löschungssession einen Prozentwert, indem die Anzahl der Betätigungen in der Löschungssitzung durch die Anzahl der Schalterbetätigungen in der letzten Trainingsstunde teilten und dann mit 100 multiplizierten, um eine Prozentzahl zu erhalten, die sie „Kumulativer Reaktionsprozentsatz“ nannten.
Würde eine Ratte in der letzten Trainingssitzung also dem Durchschnitt entsprechend 722 Mal den Schalter betätigt haben, in irgendeiner Löschungssession aber nur noch 362 mal, wäre 361 durch 722 = 0,5 x 100 = 50 % das Ergebnis. Es würde aussagen, dass in dieser speziellen Session im Vergleich zur letzten Session, in der das Verhalten positiv verstärkt wurde, nur noch halb so oft das zu löschende Verhalten gezeigt wurde.
Im folgenden Diagramm ist klar ersichtlich, dass die Gruppe, die mit 220 Volt die aversivste Strafe erhalten hat, nachhaltig den niedrigsten „Comulative Response Percentage“ aufweist und dass der Prozentsatz umso höher ausfällt, je weniger aversiv und unangenehm der Strafreiz ausfiel. Anders ausgedrückt: Fällt der Strafreiz ausreichend stark aus, zeitigt er schnell eine nachhaltige Wirkung und senkt die Auftrittswahrscheinlichkeit des bestraften Verhaltens.
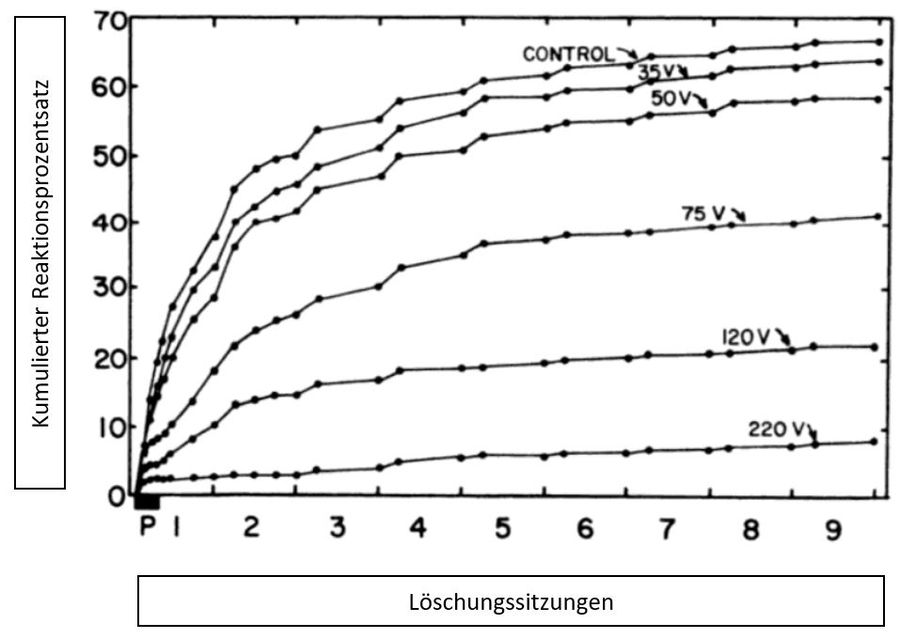
Hierzu folgten diverse Versuche, die belegen, dass eine langsame Steigerung der Intensität zu einer Gewöhnung führen, sodass trotzt Steigerung der Aversion keine Wirkungssteigerung eintrat. Es muss also von Beginn an eine Intensität gewählt werden, die ausreichend groß ist.
Strafen und Bestrafungspläne
Obwohl in dem oben beschriebenen Experiment von Boe und Church in der 15-minütigen Bestrafungsphase mit einem Bestrafungsplan gearbeitet wurde, der jeweils das erste Drücken auf den Schalter nach 30 Sekunden bestrafte, kann aus dem Experiment nicht geschlossen werden, dass ein FI-30-Strafplan der wirksamste Strafplan wäre. Zu bedenken ist nämlich, dass in dem Experiment der Verstärker komplett entzogen wurde. Wie wir im zweiten Teil der Serie sehen werden, ist das außerhalb des Labors aber nicht so einfach.
Heute geht die Forschung davon aus, dass die Auftrittswahrscheinlichkeit eines Verhaltens am schnellsten und nachhaltigsten abnimmt, wenn es immer bestraft wird. Das erleichtert dem Bestraften zu erkennen, welches Verhalten genau die Strafe hervorruft. Außerdem lässt sich eine Analogie zu den löschungsresistentesten Verstärkerplänen denken: Wenn ein Verhalten dann besonders löschungsresistent ist, wenn es nur sehr unregelmäßig und selten verstärkt wird, ist es auch löschungsresistent, wenn der Verstärker bei Zeigen des Verhaltens immer erlangt wird, eine Strafe aber nicht immer. Auch das werden wir im zweiten Teil mit einem Beispiel belegen.
Positive Strafen und zeitliche Nähe
Die Kontiguität, also die räumliche und zeitliche Nähe zwischen Reaktionen oder Verhaltensweisen einerseits und Reizen andererseits haben wir schon bezogen auf die Reiz-Reaktions-Reiz-Kopplung bei der positiven Verstärkung gesprochen. Es stellt sich aber die Frage, ob das Prinzip bei Strafen durch als Handlungsfolge verabreichten aversiven Reizen, also der positiven Strafe, ebenfalls einen großen Einfluss hat.
Der uns schon aus dem eben beschriebenen Bestrafungsexperiment bekannte Russel M. Church führte auch hierzu, unterstützt von seinen Kollegen D. S. Camp und G. A. Raymond im Jahr 1967 ein Experiment an Ratten durch, die auch hier im ersten Schritt positiv verstärkt wurden, einen Hebel in einer Skinner Box zu drücken.
Für die nun folgende Bestrafungsphase teilten sie die Ratten in vier Gruppen ein. Diesmal bekamen alle Elektroschocks in gleicher Stärke und Anzahl: Es wurde jeder zweite Hebeldruck mit einem Schock bestraft. Einziger Unterschied war diesmal die zeitliche Verzögerung: Die erste Gruppe schloss den Stromkreis durch Drücken des Hebels und sofort war der Stromstoß da. Für je eine weitere Gruppe wurde die Skinner Box so verändert, dass der Strom erst 7,5 oder 30 Sekunden nach Betätigung des Hebels durch den Boden floss. Die Kontrollgruppe erhielt verhaltensunabhängig die mittlere Anzahl an Schocks, die die anderen Gruppen erhielten.
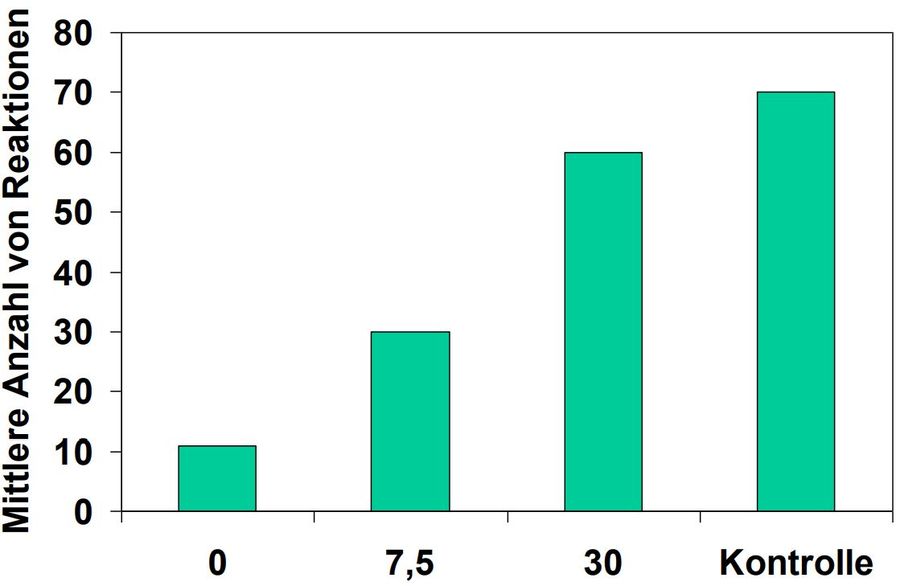
Das im obigen Diagramm erkennbare Ergebnis ist sehr eindeutig: Je kürzer die Verzögerung, desto größer der Einfluss der Strafe.
Allerdings kann man das Ergebnis auch von einer anderen Warte aus betrachten: Kommt die Strafe eine halbe Minute nach dem Verhalten oder noch später, ähneln die Auswirkungen der Strafe dem, was für die Kontrollgruppe beobachtet wurden. Und die Kontrollgruppe bekam eindeutig verhaltensunabhängig und damit nicht kontingent aversive Reize. Der Grund hierfür wurde intensiv schon beschrieben und liegt darin, dass bei großer zeitlicher Abweichung Ursache und Wirkung nicht mehr wahrgenommen werden. Welche Folgen dies haben kann, sehen wir als nächstes an.
1. Risiko: Der Bestrafende wird zum konditionierten Reiz für den aversiven Reiz der Bestrafung
Als wir uns oben mit er klassischen Konditionierung befasst haben, haben wir gelernt, dass Organismen neutrale, unbedeutende Reize durch die klassische Konditionierung so mit einem unbedingt genannten wesentlichen Reiz verbinden können, dass der neutrale Reiz denselben Reflex auslöst, wie der unbedingte. Er ist dann ein konditionierter Reiz.
Als Beispiel haben wir von Menschen gehört, die im zweiten Weltkrieg häufig erst Sirenen und kurz später Bomben explodieren hörten und auch lange Zeit nach dem Krieg noch Angstreaktionen zeigten, wenn sie eine Sirene hörten.
Gehen wir nun davon aus, dass außerhalb des Labors für einen Organismus schnell erkennbar wird, von wem eine Strafe ausgeht, wird auch klar, dass der Bestrafende selbst zum konditionierten Stimulus für die emotional und reflexhafte Reaktion auf den aversiven Reiz einer positives Strafe werden kann. Die allgemein mit einer positiven Strafe verbundene Emotionen sind Angst oder Wut und Aggression die über die beschriebene Kopplung mit dem Strafenden verbunden werden kann.
Setzt man voraus, dass im Normalfall die Hundhalter, Eltern, Lehrer, Trainer Strafen verhängen und somit die Strafenden sind, stellt sich die Frage, welche Auswirkungen die mit ihnen verbundenen Emotionen wie Angst vor den genannten Personen auf das Lernen via Konditionierung haben kann.
2. Risiko: Die negative Auswirkung der Angst auf das Lernvermögen
Dass Angst im Allgemeinen und vor dem Herrchen im besonderen ein Problem für die Lernfähigkeit des Hundes darstellt, kann bereits aus Arbeiten von Skinner und seinem Doktorand Estes im Jahr 1941 abgeleitet werden.
In einem Experiment verstärkten sie bei ihren Versuchstieren ein Verhalten positiv, bis dieses Verhalten eine stabil hohe Auftrittsrate hatte. Nachdem dies erreicht war, wurde über die klassische Konditionierung ein Hinweisreiz mit einem aversiven Reiz dargeboten, natürlich unabhängig vom aktuellen Verhalten der Probenaden. Nach einigen Sitzungen konnten Estes und Skinner beobachten, dass das konditionierte Verhalten in Folge des Hinweisreizes seltener gezeigt wurde, auch wenn kein aversiver Reiz mehr gezeigt wurde.
Auch wenn Skinner in seinen Theorien keine Aussagen über die inneren Vorgänge machen wollte, spricht man heute hierbei von konditionierter emotionaler Reaktion und meint damit im vorliegenden Beispiel, dass in Erwartung eines aversiven Reizes die Emotion Angst ausgelöst wird und in Folge dieser die Reaktionsrate für ein bereits konditioniertes Verhalten abnimmt.
Wenn bereits konditioniertes Verhalten unter Angst abnimmt, kann geschlossen werden, dass es umso schwieriger wird, einen angstempfindenden Organismus auf ein neues Verhalten zu konditionieren. Seine Lerngeschwindigkeit nimmt also ab.
3. Risiko: Durch Modelllernen wird der Bestrafte aggressiver
Unter Modelllernen wird verstanden, dass ein Organismus sich ein Verhalten durch Imitation des Verhaltens eines anderen Organismus aneignet.
Bezogen auf unser Thema der positiven Strafe besteht insofern das Risiko, dass der bestrafte Organismus sich die positive Bestrafung, die ein Akt der Aggression darstellt, selbst aneignet, um seinerseits häufiger über aggressives Verhalten Situationen zu lösen.
4. Risiko der positiven Bestrafung: Gelernte Hilflosigkeit durch mangelhafte Kontingenz
Wir haben gesehen, was notwendig ist, damit eine positive Strafe einen Effekt zeigt. Nun schauen wir uns an, welche Risiken mit der Anwendung einhergehen, wissend, dass wir eine positive Strafe nur dann effektiv anwenden können, wenn der aversive Reiz, den wir verabreichen, von Beginn an ausreichend stark ist.
Positive Strafen und die Folgen fehlender Kontingenz
Kontingenz beschreibt die Vorhersehbarkeit von Reiz-Reaktions-Kopplungen, im Fall der Strafen also die Vorhersagbarkeit, dass ein bestimmtes Verhalten eine Strafe nach sich ziehen wird. Wie wir eben gesehen haben, ist sie besonders leicht zu erkennen, wenn eine große Zeitnähe vorhanden ist und jedes Mal, wenn das Verhalten auftritt der entsprechende Reiz folgt. Nun stellt sich die Frage, welche Auswirkungen es hat, wenn die Kontingenz nicht erkannt wird. Dies kann geschehen, weil die beiden genannten Eingangsparameter nicht zulassen, weil die Strafe zu unregelmäßig und jeweils mit zu großem zeitlichen Abstand zum entsprechenden Verhalten erfolgt. Um die Auswirkungen experimentell messen zu können, war in den gleich beschriebenen Experimenten schlicht gar keine Kontingenz vorhanden.
Das erste Experiment
Für das erste Experiment wurden die Versuchstiere in eine Versuchs- und eine Kontrollgruppe eingeteilt. Das Experiment war in vier Phasen unterteilt. In der ersten Phase wurden die Tiere beider Gruppen mittels positiver Verstärkung auf ein bestimmtes Verhalten konditioniert. In der zweiten Phase wurde der Versuchsgruppe verhaltensunabhängige und damit nicht kontingente Elektroschocks verabreicht. In Phase drei wurde das Verhalten erneut über positive Verstärkung trainiert, um in der letzten Phase eine mit Bestrafung einhergehende Löschung des Verhaltens zu bewirken. In dieser Phase war die Bestrafung klar erkennbar an das Verhalten gekoppelt: jedes Verhalten wurde bestraft und keine zeitliche Verzögerung lag zwischen Verhalten und Strafreiz.
Aus dem unten stehenden Diagramm, in dem die Kontrollgruppe rot und die Versuchsgruppe blau dargestellt ist, ist klar erkennbar, dass die blaue Gruppe im Gegensatz zu der roten während der Phase der verhaltensabhängigen, kontingenten Bestrafung das bestrafte Verhalten nicht verringerte.
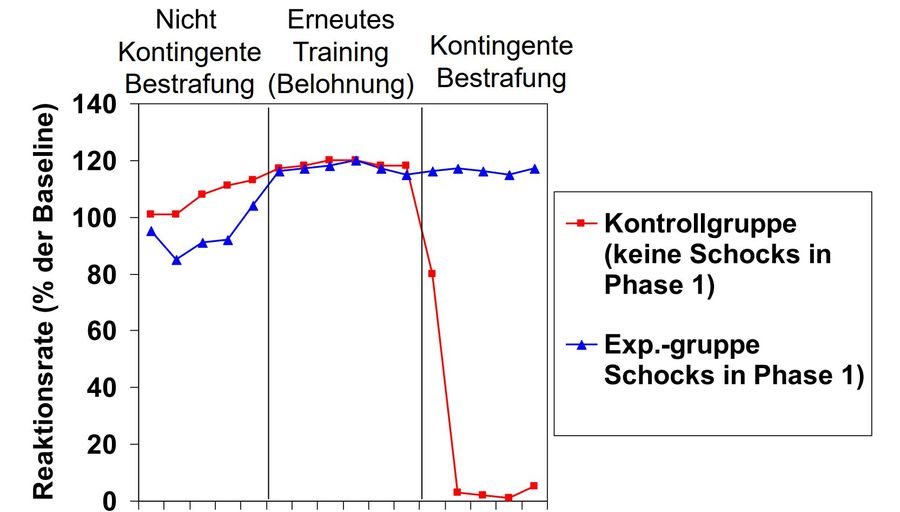
Aus dem Ergebnis solcher Experimente lässt sich also schließen, dass das Erleiden verhaltensunabhängiger unangenehmer Reize die Fähigkeit einschränkt, zu erkennen, wann ein unangenehmer Reiz vom eigenen Verhalten abhängt und somit vermieden werden kann. Anders ausgedrückt, führen fehlerhaft, insbesondere bezogen auf die zeitlichen Aspekte und Bestrafungspläne, aber in ausreichender Intensität ausgeführte positive Bestrafungen dazu, dass Strafen ihre verhaltensändernde Wirkung verlieren.
Das zweite Experiment
Nun stellt sich die Frage, ob verhaltensunabhängige aversive Reize nur die Wirkung von Strafen mindern, oder weitere Auswirkungen auf die Lernfähigkeit feststellbar sind.
Unter anderem diesem Thema widmeten sich J. Bruce Overmier von der University of Minnesota und Marin E. P. Seligman von der University of Pennsylvania in einer Arbeit von 1967, in der sie ihre vorangegangenen Experimente mit Hunden beschrieben.
Für das erste Experiment wurden 32 ausgewachsene Mischlingshunde in vier Gruppen zu je acht Hunden aufgeteilt, von denen die erste Gruppe die Kontrollgruppe und die übrigen drei Versuchsgruppen waren. Für die Versuche standen Boxen zur Verfügung, die mit einer von den Hunden überspringbaren Mauer in zwei gleichgroße Hälften geteilt waren. Der Boden der einen Hälfte war elektrifizierbar, die andere nicht. Die Versuche wurden in zwei Phasen geteilt.
In der ersten Phase wurden alle Hunde in dem Teil elektrifizierbaren Teil der Box in einer Art Hängematte derart fixiert, dass ihnen keine Bewegungsfreiheit mehr blieb. Nun wurde den Hunden der Versuchsgruppen Stromschläge als aversive Reize verabreicht, die sie durch ihr Verhalten in keiner Weise beeinflussen konnten. Je nach Versuchsgruppe unterschied sich die Art und Weise, wie die Schocks verabreicht wurden: in Gruppe II wenige längere in längeren Abständen oder in Gruppe III viele kurze in kürzeren Abständen oder in Gruppe IV wenige kurze in längeren Abständen. Aber eines ist hier entscheidend: Es wird auf diese Weise eine nicht kontingente positive Bestrafung nachgeahmt.
Einen Tag später wurden die Hunde aller Gruppen in denselben Boxen einem Vermeidungstraining mit 10 Wiederholungen unterzogen. Dabei kündigte ein Hinweisreiz, in dem Fall das Dimmen der Innenbeleuchtung, den 10 Sekunden später beginnenden und maximal 60 Sekunden lang fließenden Strom an. Durch einen Sprung über die kleine Mauer in die andere Hälfte des Käfigs konnte der betreffende Hund nun dem Stromschock entgehen.
Nun müssen wir kurz innehalten und uns in Erinnerung rufen, welche der bisher beschriebenen Techniken hier zur Anwendung kommen. Die Kombination aus gedimmtem Licht, das erst wieder heller wird, wenn der später einsetzende Stromfluss endet, entspricht der klassischen Konditionierung Pawlows: Der unbedeutende Reiz des dunkler werdenden Lichts wird mit dem bedeutenden Schmerzreiz des Stromschlags verbunden, wodurch das gedimmte Licht nach einigen Wiederholungen zum konditionierten Reiz wird.
Andererseits stellt der Stromfluss einen aversiven Reiz dar, den der Hund durch eigenes Verhalten, in dem Fall durch das Fluchtverhalten des Sprungs in die andere Hälfte des Käfigs, für sich beenden kann. Das entspricht Skinners negativer Konditionierung, auf die wir später nochmal eingehen werden.
Kombiniert man diese beiden Techniken, sollte das Ergebnis Vermeidungsverhalten sein: Der Hund wird klassisch darauf konditioniert, das gedimmte Licht als Ankündigung für den aversiven Reiz zu deuten. Gleichzeitig wird er negativ konditioniert, dem aversiven Reiz zu durch Flucht zu entkommen. Nun kann er Vermeidungsverhalten an den Tag legen, indem er innerhalb der 10 Sekunden, die zwischen dem Dimmen und dem Start des Stromflusses vergehen, in die andere Hälft springt: Er wird dadurch den aversiven Stromschock für sich vermeiden können.
Nun schauen wir auf die Ergebnisse des Tests in Form einer Tabelle, wobei die Spalte „Latenz in Sekunden“ die Zeit angibt, die durchschnittlich in der betreffenden Gruppe zwischen Dimmen des Lichts und Sprung in die andere Hälfte des Käfigs benötigt wurden.
|
Gruppe |
Durchschnittliche Latenz/Reaktionszeit in Sekunden | Prozentsatz der Hunde, die nie dem Schock entkamen |
| Kontrollgruppe I | 22,19 | 12,5 |
| Versuchsgruppe II | 54,21 | 65,5 |
| Versuchsgruppe III | 46,19 | 50,0 |
| Versuchsgruppe IV | 38,67 | 35,5 |
Zur Interpretation der Daten schrieben die beiden Forscher, dass klar erkennbar sei, dass die Tiere der Versuchsgruppen den Schmerz deutlich länger ohne Fluchtreaktion annahmen, als die Tiere der Kontrollgruppe.
Sie variierten dieses Grundexperiment dann zweimal, um damals vorgeschlagene Theorien für diese Beobachtung auszuschließen, was wir uns hier ersparen wollen.
Was wir uns nicht ersparen möchten, sind die geschilderten Beobachtungen, die abseits der reinen Zahlen von Overmier und Seligman dokumentiert wurden. Sie schrieben, dass ein „dramatisch zu beobachtender Unterschied im Verhalten“ der Hunde aus der Kontrollgruppe und den Hunden der Versuchsgruppen vorläge: Als die Hunde der Kontrollgruppe in der Konditionierungsphase erstmalig den Strom spürten, bellten und winselten sie, sie rannen und sprangen, bis sie dem Strom entkommen waren. Die Hunde der Versuchsgruppen verhielten sich ganz ähnlich, als sie erstmalig den Strom spürten: Anfänglich bellten und winselten sie, laufen und springen konnten sie nicht. Schon bald stellten sie das Bellen und Winseln ein und hielten still, bis der Stromschmerz endete. Entsprechend verhielten sie sich später, als sie dem Schmerz durch einen Sprung in die andere Hälfte des Käfigs hätten entkommen können. Auch wenn das Gelegentlich von einem der betreffenden Hunde getan wurde, erhöhte das für den nächsten Durchgang nicht die Wiederholungswahrscheinlichkeit, was ein weiterer signifikanter Unterschied zur Kontrollgruppe war: Die Hunde, die einmal durch den Sprung in die andere Hälfte des Käfigs den Schmerzreiz beendet hatten, sprangen bei den folgenden Durchgängen mit höherer Wahrscheinlichkeit und schneller über die Mauer. Explizit hielten die beiden Forscher fest, dass die betreffenden Hunde physisch zu einem Sprung in die andere Käfighälfte in der Lage waren: Ohne Strom sprangen sie problemlos bei der einen oder anderen Gelegenheit über die Mauer.
Die Theorie der gelernten Hilflosigkeit
Rund 10 Jahre brauchte Seligman, nun unterstützt von Steven F. Maier, um auf den schon beschriebenen und weiteren Experimenten, auch mit Menschen, die Hypothese der gelernten Hilflosigkeit zu formulieren. Diese Hypothese besagt, dass unkontrollierbare aversive Reize auf tierische Lebewesen sich auf Motivation, Kognition und Emotion negativ auswirken. Im Wesentlichen besagt diese Hypothese, dass ein Lebewesen, das gelernt hat, dass sein Verhalten keinen Einfluss auf die verabreichten aversiven Reize hat, dazu tendiert, in Apathie zu verfallen. Es ist annähernd unfähig, neues zu lernen, da es annimmt, dass alles Verhalten keinen Einfluss hat.
Ist die negative Strafe genauso risikoreich?
Die negative Bestrafung ist mit deutlich weniger Risiken verbunden. Der Grund hierfür liegt darin, dass der Entzug eines angenehmen Reizes oder Verhaltensmöglichkeit nicht im selben Maße angsteinflößend ist, wie die Verabreichung eines ausreichend intensiven aversiven Reizes.
Dennoch spielt auch bei der negativen Strafe die Kontingenz eine wichtige Rolle, weshalb immer eine zeitliche Nähe zwischen der Verhaltensweise und der Strafe liegen muss. Auch hier herrscht die Meinung vor, dass eine Immerbestrafung der effektivste Bestrafungsplan ist.
Ähnlichkeiten der Strafen und negativen Verstärkung
Um die Ähnlichkeiten zwischen Strafe und negativer Verstärkung darzustellen, möchte ich nochmal auf das Ergebnis der Kontrollgruppe des in Wigdet 4 beschriebenen Experiments verweisen.
| Gruppe | Durchschnittliche Reaktionszeit/Latenz in Sekunden | Prozentsatz der Hunde, die nie dem Schock entkamen |
| Kontrollgruppe I | 22,19 | 12,5 |
Wir erinnern uns, dass die Kontrollgruppe dieses Experiments einzig einer negativen Konditionierung unterzogen wurde. Wie in der Tabelle zu sehen ist, haben aber 12,5 % dieser Tiere es nie geschafft, dem Schock durch das zu konditionierende Verhalten, also durch das Springen in die andere Hälfte des Käfigs, zu entkommen.
Von diesen 12,5 % der Tiere kann angenommen werden, dass sie statt des zu konditionierten Verhaltens Hilflosigkeit gelernt haben. Die Auswirkungen der gelernten Hilflosigkeit sind hier ausführlich besprochen worden, sodass dem geneigten Leser das Risikopotential der negativen Konditionierung klar geworden sein sollte.
Was bedeutet das alles für die Hundeerziehung?
Wie überträgt man die Theorie in die Praxis?
Nachdem wir jetzt ein tiefes Verständnis für die Entwicklung der Verhaltensforschung, ihre Grundbegriffe und Zusammenhänge entwickelt haben, wird es im nächsten Teil der Serie Zeit zu schauen, was das für die Hundeerziehung oder besser: für das Zusammenleben mit einem Hund, bedeutet.
Hat dir der Inhalt gefallen? Dann teile ihn doch auch mit anderen: